Capitolo 2 Progettare un esperimento
2.1 Gli elementi della ricerca
Nel capitolo precedente abbiamo visto che ogni esperimento, per essere valido, deve conformarsi a tre principi di base, cioè la replicazione, la randomizzazione e il controllo. Non è facile spiegare come si mettano in atto questi principi e, certamente, non esiste una risposta generalmente valida; l’esperienza gioca un ruolo fondamentalmente e, quando si muovono i primi passi, è sempre bene cercare l’aiuto di un collega più anziano.
In questo capitolo prenderemo in esame una serie di elementi che riguardano tutti gli esperimenti scientifici, indipendentemente dalla disciplina e dalle finalità. Per la loro importanza, ognuno di questi elementi richiederà decisioni opportune in fase di pianificazione e dovrà essere accuratamente dettagliato in ogni progetto o rapporto di ricerca, per permettere la valutazione della bontà della ricerca stessa. Questi elementi sono:
- ipotesi ed obiettivi
- fattore/i sperimentale/i;
- soggetti sperimentali (unità sperimentali);
- allocazione dei trattamenti;
- le variabili sperimentali.
2.2 Ipotesi scientifica \(\rightarrow\) obiettivo dell’esperimento
Trascurando la ricerca bibliografica, che è pur fondamentale, nel metodo scientifico galileiano, il punto di partenza di un esperimento è l’ipotesi scientifica, dalla quale discende tutto il lavoro successivo. Questa ipotesi deve essere rilevante, chiaramente definita e specifica; insomma, dobbiamo aver individuato con chiarezza una connessione tra eventi che potrebbe essere spiegata da una relazione causa-effetto. Un ipotesi, solitamente si pone in forma dubitativa: “la germinazione di un lotto di semi potrebbe dipendere dall’adozione di un certo metodo di priming”; oppure: “la produttività di una coltura potrebbe migliorare con l’adozione di una maggiore fittezza d’impianto”.
Dall’ipotesi, in modo consequenziale scaturiscono gli obiettivi della ricerca, cioè le domande alle quali la ricerca intende dare risposta. Questi obiettivi dovranno essere raggiungibili/realistici e temporalmente organizzati; inoltre, dovrà essere possibile capire se e quando siano stati raggiunti attraverso un qualche indicatore misurabile.
Il rischio che si corre con obiettivi mal posti è quello di eseguire una ricerca dispersiva, con raccolta di dati non necessari e/o mancanza di dati fondamentali, con costi più elevati del necessario e un uso poco efficiente delle risorse. In genere, prima si definisce un obiettivo generale, poi si definiscono uno o più obiettivi specifici, proiettati su un più breve spazio temporale, anche per marcare le fasi necessarie per raggiungere l’obiettivo generale.
Non è un caso se, in un lavoro scientifico, gli obiettivi della ricerca sono posti in fondo all’introduzione, appena prima dell’esposizione dei materiali e metodi.
2.3 Identificazione dei fattori sperimentali
A differenza degli esperimenti osservazionali, più tipici delle scienze mediche e sociali, dove ci si limita ad osservare quanto accade in natura, gli esperimenti manipolativi sono basati appunto sulla ‘manipolazione’ dei soggetti sperimentali, che vengono sottoposti a stimoli differenti, a seconda della risposta che si vuole valutare.
Dopo aver definito l’obiettivo di un esperimento, pertanto, è necessario chiarire esattamente quali saranno gli stimoli ai quali sottoporremo le unità sperimentali. Uno ‘stimolo’ sperimentale prende il nome di fattore sperimentale, che può avere più livelli, detti trattamenti (o tesi) sperimentali. Ad esempio, se l’obiettivo è quello di valutare l’effetto della temperatura sulla germinazione dei semi di quinoa, il fattore sperimentale sarà la temperatura, con tre livelli, 10, 15 e 25°C, ai quali verranno sottoposte le capsule Petri incluse in prova.
2.3.1 Esperimenti (multi-)fattoriali
Talvolta gli obiettivi dell’esperimento comportano lo studio di più di un fattore sperimentale; ad esempio, oltre che alla temperatura, potremmo anche essere interessati a studiare l’effetto dell’umidità sulla germinazione dei semi. In questo caso potremmo pianificare due esperimenti separati oppure un unico esperimento, in cui prendiamo in considerazione entrambi i fattori sperimentali. Un esperimenti di questo tipo si dice fattoriale, o meglio, multi-fattoriale ed i fattori possono essere incrociati (crossed) oppure innestati. Nel primo caso includeremo in prova tutte le possibili combinazioni tra i livelli di ogni fattore. Ad esempio, se volessimo studiare il comportamento di tre varietà di girasole (A, B e C) con due tipi di concimi (pollino e urea), potremmo disegnare un esperimento con 6 trattamenti, rappresentati da tutte le possibili combinazioni di varietà e concimi, cioè A-pollina, A-urea, B-pollina, B-urea, C-pollina e C-urea.
In un disegno a fattori innestati, invece, i livelli di un fattore cambiano al cambiare dei livelli dell’altro. Ad esempio, se volessimo confrontare tre varietà di frumento in due sistemi colturali (convenzionale e biologico), potremmo decidere di utilizzare varietà diverse in sistemi diversi, alla ricerca del miglior adattamento possibile per una certa specie. In questo caso avremmo comunque sei trattamenti, ma le combinazioni sarebbero: biologico-A, biologico-B, biologico-C, convenzionale-D, convenzionale-E e convenzionale-F.
Il vantaggio degli esperimenti fattoriali è che permettono di valutare la presenza di ‘interazione’, un fenomeno che si produce quando le combinazioni tra alcuni dei livelli inclusi in prova per ogni fattore producono risposte inattese, particolarmente buone o cattive rispetto a quello che avremmo potuto attenderci, considerando i due fattori sperimentali uno separatamente dall’altro. Ad esempio, se considerassimo le due varietà di mais A e B, con A mediamente più produttiva di B, coltivate in due annate, ad esempio 2025 e 2026, con la seconda molto più sfavorevole, perché siccitosa, dovremmo aspettarci che la combinazione A-2025 fornisca i migliori risultati, mentre la combinazione B-2026 fornisca i peggiori. Se questo non avviene, ad esempio perché B è particolarmente adatta a resistere alla siccità, allora abbiamo un fenomeno d’interazione, che è molto importante studiare nel dettaglio, con un esperimento fattoriale.
2.3.2 Controllo o testimone
In alcuni casi è necessario inserire in prova un trattamento che funga da riferimento per tutti gli altri; questo trattamento è comunemente detto controllo o testimone. Possiamo avere:
- controllo non trattato
- controllo trattato con placebo
- controllo trattato secondo le modalità usuali
Il controllo cosiddetto ‘non trattato’ è tipico degli esperimenti in ambito fitopatologico, ad esempio quando si vogliono confrontare sostanze chimiche caratterizzate da attività biologica contro un certo organismo. In questi esperimenti, si include sempre un controllo non trattato, che ci permette di capire quale sarebbe stato lo sviluppo dell’organismo sensibile in assenza del trattamento. Nelle prove di confronto erbicida, in assenza del controllo non trattato, non saremmo in grado di stabilire l’efficacia degli erbicidi di pre-emergenza, perché non sapremmo mai se l’assenza delle piante infestanti sia dovuta all’effetto del diserbo o ad altri effetti ambientali.
In alcuni casi, il soggetto è influenzabile e può reagire alla semplice idea di essere stato trattato. Ciò capita soprattutto con soggetti umani in ambito medico e, pertanto, invece che il controllo non trattato, si preferisce utilizzare un controllo trattato con placebo, cioè una preparazione che contiene tutti gli ingredienti della formulazione, meno che il principio attivo. In ambito agrario non si parla di placebo, ma talvolta si impiegano formulazioni senza principio attivo con funzioni di controllo, quando si sospetti che i co-formulanti o la soluzione impiegata per veicolare il principio attivo possano mostrare un qualche effetto biologico sul soggetto. Ad esempio, se volessimo provare un erbicida miscelato con un olio minerale, che ha di per se’ un certo effetto sulla flora infestante, dovremmo includere sia un controllo non trattato, che un controllo trattato solo con olio minerale.
In altri casi, i trattamenti sperimentali non sono costituiti da trattamenti chimici e, pertanto, non possiamo parlare di controllo non trattato. Anche in questi casi, tuttavia, può sussistere la necessità di avere un riferimento, contro il quale valutare l’efficacia, per esempio, di una tecnica agronomica innovativa. In questi casi siamo soliti includere in prova una tecnica di riferimento, che di solito è quella più consolidata negli usi locali; ad esempio, in un confronto varietale, viene sempre inclusa una varietà di riferimento locale, che ci consente di capire se le prestazioni delle varietà innovative siano effettivamente interessanti oppure no. Diversamente, non saremmo in grado di capire se le produzioni osservate siano dovute al genotipo, oppure ad effetti ambientali favorevoli/sfavorevoli.
Un altro esempio importante è relativo alle prove di diserbo, nelle quali, oltre al controllo non trattato, viene spesso inserito un controllo scerbato manualmente, che diviene il riferimento per valutare potenziali effetti fitotossici verso la coltura.
2.4 Le unità sperimentali
L’unità sperimentale è l’entità fisica che riceve il trattamento sperimentale; può essere una pianta, un animale, un vaso, una capsula Petri o ogni altra entità di rilievo per lo studio in atto. Le unità sperimentali non vanno confuse con le unità osservazionali, perché le due entità non sempre coincidono. Ad esempio, noi potremmo allocare il trattamento erbicida ad un vaso e poi misurare l’altezza delle singole piante trattate; in questo caso il vaso è l’unità sperimentale (perché ha subito il trattamento), mentre la pianta è l’unità osservazionale. Avere chiara questa differenza è fondamentale per evitare problemi di pseudo-replicazione, come abbiamo dettagliato nel capitolo precedente.
Le unità sperimentali sono sempre selezionate da una popolazione più grande, detta cornice di campionamento; ad esempio, noi selezioniamo le parcelle da un campo, gli animali da una mandria e le piante da una coltura. Comunque sia, il campione selezionato deve essere omogeneo e rappresentativo, anche se i due concetti sono spesso discordanti. Infatti, se selezioniamo soggetti molto omogenei, potremmo ottenere un campione che non rappresenta più tutte le caratteristiche della cornice di campionamento. Ad esempio, se selezioniamo solo individui maschi in buona salute, il campione non necessariamente rappresenta l’intera popolazione, se composta anche da femmine e da soggetti con patologie in atto.
Campionare una popolazione d’interesse non è un procedimento banale, specie nelle scienze sociali, laddove è stato necessario definire diversi protocolli di campionamento (casuale, sistematico, stratificato, a quota …), per i quali si rimanda ai testi specializzati (ad esempio, Daniel 2011). In questo libro noi facciamo riferimento soprattutto alle prove di pieno campo e di laboratorio. Per le prime, la selezione delle unità sperimentali corrisponde fondamentalmente con la selezione dell’appezzamento di prova e l’identificazione delle parcelle, di cui parleremo tra poco.
Per le prove di laboratorio, invece, la situazione può essere abbastanza diversa, in quanto le unità sperimentali sono specificatamente create per un certo esperimento (vasetti, capsule Petri ad altri preparati). Di conseguenza, non vi è un vero e proprio processo di selezione, il che, tuttavia, non significa che non ci sia campionamento. Infatti, anche le unità sperimentali preparate in laboratorio debbono comunque essere considerate come campionate da un universo più grande, costituito da tutte le altre unità sperimentali che avremmo potuto preparare.
2.5 Allocazione dei trattamenti
Il problema dell’allocazione dei trattamenti non si pone con gli esperimenti osservazionali, in quanto con questi si scelgono unità sperimentali già ‘naturalmente’ trattate.
Per tutti gli esperimenti manipolativi si pone invece il problema di scegliere quali soggetti trattare e come. In generale, seguendo il principio Fisheriano di randomizzazione, l’allocazione dei trattamenti dovrebbe essere effettuata scegliendo le unità sperimentali completamente a caso (esperimenti completamente randomizzati). Tuttavia vedremo che in molte circostanze è conveniente porre dei vincoli al processo di randomizzazione, il che non è sbagliato se questi vincoli sono tenuti in debita considerazione durante il processo di analisi dei dati (Analyse them as you have randomised them! R. Fisher). Questi vincoli costituiscono la base del disegno sperimentale di cui parleremo tra breve.
In alcuni casi è opportuno nascondere i dettagli dell’allocazione dei trattamenti. Parliamo quindi di esperimento cieco, quando i soggetti non sono coscienti del trattamento che ricevono o doppio cieco, quando neanche i ricercatori lo sono. Un esperimento cieco o doppio cieco è necessario quando sapere quale trattamento è stato allocato può provocare effetti inconsci o indurre errori di valutazione nel ricercatore. Quest’ultimo caso è importante anche nelle scienze agrarie, dove sapere con che principio attivo è stata diserbata una parcella può indurre preconcetti in chi deve realizzare un rilievo visivo.
2.6 Le variabili sperimentali
Per ogni singolo carattere, l’insieme delle modalità/valori che ognuno dei soggetti presenta prende il nome di variabile (proprio perché varia, cioè assume diversi valori, a seconda del soggetto). In questo senso è necessario precisare che non è corretto utilizzare il termine parametri, in quanto in statistica i parametri sono entità che rimangono costanti all’interno di una popolazione di soggetti. Ne parleremo meglio nei prossimi capitoli.
Fondamentalmente, esistono due grandi gruppi di variabili: quelle che definiscono lo ‘stimolo’ sperimentale e quelle che misurano la risposta dei soggetti trattati. Le variabili che definiscono uno ‘stimolo’ sperimentale sono anche dette variabili ‘indipendenti’ in quanto non dipendono da nessun altro elemento interno all’esperimento, a parte la volontà dello sperimentatore. Di queste variabili abbiamo già parlato, in quanto esse sono definite all’inizio dell’esperimento e rappresentano i livelli del/dei trattamento/i sperimentali, ad esempio, le modalità di lavorazione del suolo (aratura, minima lavorazione, semina su sodo) o il valore di azoto apportato (0, 50, 100, 150 kg N ha-1).
Durante e al termine dell’esperimento vengono invece rilevate le variabili ‘risposta’ che esprimono l’effetto dei trattamenti sperimentali, come, ad esempio, la produzione della coltura, il peso delle piante trattate con un diserbante, la quantità di azoto lisciviato dopo la fertilizzazione. Queste variabili vengono normalmente definite ‘dipendenti’, in quanto i valori assunti da ogni unità sperimentale dipendono, normalmente’ dallo stimolo che hanno ricevuto.
Sia le variabili indipendenti che quelle dipendenti possono essere di diversi tipi, che dobbiamo saper riconoscere per scegliere che tipo di analisi statistica da eseguire. In particolare, distinguiamo:
- variabili nominali (categoriche);
- variabili ordinali;
- variabili quantitative discrete;
- variabili quantitative continue.
2.6.1 Variabili nominali (categoriche)
Le variabili nominali esprimono, per ciascun soggetto, l’appartenenza ad una determinata categoria o raggruppamento ed il valore che assumono lo definiamo modalità. L’unica caratteristica delle modalità è l’esclusività, cioè un soggetto che ha una certa modalità non può averne nessun altra. Le variabili nominali sono, ad esempio, il sesso, la varietà, il tipo di diserbante impiegato, la lavorazione e così via. Le variabili categoriche permettono di raggruppare i soggetti, ma non possono essere utilizzate per fare calcoli, se non per definire le frequenze dei soggetti in ciascun gruppo.
2.6.2 Variabili ordinali
Anche le variabili ordinali esprimono, per ciascun soggetto, l’appartenenza ad una determinata categoria o raggruppamento. Tuttavia, le diverse categorie sono caratterizzate, oltre che dall’esclusività, anche da una relazione di ordine, nel senso che è possibile stabilire una naturale graduatoria tra esse. Ad esempio, la risposta degli agricoltori a domande relative alla loro percezione sull’utilità di una pratica agronomica può essere espressa utilizzando una scala con sei categorie (0, 1, 2, 3, 4 e 5), in ordine crescente da 0 a 5 (scala Likert). Di conseguenza possiamo confrontare categorie diverse ed esprimere un giudizio di ordine (2 è maggiore di 1, 3 è minore di 5), ma non possiamo eseguire operazioni matematiche, tipo sottrarre dalla categoria 3 la categoria 2 e così via, dato che la distanza tra le categorie non è specificata e, soprattutto, non è necessariamente la stessa.
2.6.3 Variabili quantitative discrete
Le variabili discrete sono caratterizzate dal fatto che possiedono, oltre alle proprietà dell’esclusività e dell’ordine, anche quella dell’equidistanza tra gli attributi (es., in una scala a 5 punti, la distanza – o la differenza – fra 1 e 3 è uguale a quella fra 2 e 4 e doppia di quella tra 1 e 2). Una tipica variabile discreta è il conteggio di piante infestanti all’interno di una parcella di terreno. Anche le proporzioni sono da considerare variabili discrete, in quanto non possono assumere valori nell’ambito dei numeri reali.
Le variabili discrete consentono la gran parte delle operazioni matematiche e permettono di calcolare molte importanti statistiche come la media, la mediana, la varianza e la deviazione standard.
2.6.4 Variabili quantitative continue
Le variabili quantitative continue possiedono tutte le proprietà precedentemente esposte (esclusività delle categorie, ordine, distanza) oltre alla continuità, almeno in un certo intervallo. Tipiche variabili continue sono l’altezza, la produzione, il tempo e la fittezza.
Dato che gli strumenti di misura, nella realtà, sono caratterizzati da una risoluzione non infinita, si potrebbe arguire che le variabili continue, in pratica, non esistano. Tuttavia questo argomento è più teorico che pratico e, nella ricerca biologica, consideriamo continue tutte le variabili misurate con strumenti caratterizzati da un risoluzione sufficientemente buona rispetto alla grandezza da misurare. Insomma, se dobbiamo misurare l’altezza del mais ed utilizziamo un metro da sarto, possiamo ottenere una variabile che può essere considerata continua.
Talvolta, per esigenze di rappresentazione, le variabili continue possono essere espresse su una scale qualitativa, adottando un’opportuna operazione di classamento. Il contrario, cioè trasformare in quantitativa una variabile qualitativa, non è invece possibile.
2.6.5 Rilievi visivi e sensoriali
Nella pratica sperimentale è molto frequente l’adozione di metodi di rilievo basati sull’osservazione di un fenomeno attraverso uno dei sensi (più spesso, la vista, ma anche gusto e olfatto) e l’assegnazione di una valutazione su scala categorica, ordinale o, con un po’ di prudenza, quantitativa discreta o continua. Ad esempio, il ricoprimento delle piante infestanti, la percentuale di controllo di un erbicida e la sua fitotossicità vengono spesso rilevati visivamente, su scale da 0 a 100 o simili.
I vantaggi di questa tecnica sono molteplici:
- Basso costo ed elevata velocità
- Possibilità di tener conto di alcuni fattori perturbativi esterni, che sono esclusi dalla valutazione, contrariamente a quello che succede con metodi oggettivi di misura
- non richiede strumentazione costosa
A questi vantaggi fanno da contraltare alcuni svantaggi, cioè:
- Minor precisione (in generale)
- Soggettività
- L’osservatore può essere influenzabile
- Difficoltà di mantenere uniformità di giudizio
- Richiede esperienza specifica e allenamento
I rilievi sensoriali sono ben accettati nella pratica scientifica in alcuni ambiti ben definiti, anche se richiedono attenzione nell’analisi dei dati non potendo essere assimilati tout court con le misure oggettive su scala continua.
2.6.6 Variabili di confondimento
Quando si pianificano i rilievi da eseguire, oppure anche nel corso dell’esecuzione di un esperimento, bisogna tener presente non soltanto la variabile che esprime l’effetto del trattamento, ma anche tutte le variabili che misurano possibili fattori di confondimento.
Ad esempio, immaginiamo di voler valutare la produttività di una specie arborea in funzione della varietà. Immaginiamo anche di sapere che, per questa specie, la produttività dipende anche dall’età. Se facciamo un esperimento possiamo utilizzare alberi della stessa età per minimizzare la variabilità dei soggetti. Tuttavia, se questo non fosse possibile, per ogni albero dobbiamo rilevare non solo la produttività, ma anche l’età, in modo da poter valutare anche l’effetto di questo fattore aggiuntivo e separarlo dall’effetto della varietà. In questo modo l’esperimento diviene molto più preciso.
2.7 Esperimenti di campo
Una volta che tutti gli elementi della ricerca sono stati attentamente pianificati possiamo realizzare l’esperimento. Le tecniche che utilizzeremo saranno fortemente dipendenti dalla discipline, dagli obiettivi, dalla scala (esperimento di laboratorio, serra, campo…) e non è possibile dare indicazioni generali, a parte che ogni esperimento valido deve essere controllato, replicato e randomizzato. In questo capitolo parleremo solo di esperimenti di pieno campo, che costituiscono un elemento fondamentale della ricerca in agricoltura. Tuttavia, si può ragionevolmente ritenere che la gran parte delle informazioni che troverete sono valide anche per altri tipi di esperimenti.
2.7.1 Scegliere il campo
Per quanto riguarda la sperimentazione di pieno campo, l’omogeneità dell’ambiente è fondamentale per aumentare la precisione dell’esperimento, cosa che si consegue, innanzitutto, con la scelta dell’appezzamento giusto. Questa scelta è particolarmente delicata ed è guidata soprattutto dall’esperienza, tenendo conto anche di aspetti come la facilità di accesso e la vicinanza di strutture (laboratori, capannoni…), che consentano un’accurata esecuzione degli eventuali prelievi. In genere, si cerca di non avvicinarsi troppo alle scoline, dove possono manifestarsi ristagni idrici, oppure a zone del campo che presentino evidenti segni di difformità.
Oltre a scegliere correttamente l’appezzamento, è importante anche porre in atto alcune operazioni preliminari che consentano di migliorare l’omogeneità del campo o della coltura. Ad esempio, talvolta si usa far precedere la prova da una coltura come l’avena, che è molto avida di azoto e lascia nel terreno poca fertilità residua. Oppure, si può impiantare un prato di erba medica, che, grazie agli sfalci periodici, lascia il terreno libero da piante infestanti. Un’altra tecnica molto usata è quella di seminare a densità più alte del normale e poi diradare, per assicurare una migliore uniformità d’impianto.
2.7.2 Le unità sperimentali in campo
Dopo aver scelto il campo dobbiamo scegliere le unità sperimentali, distinguendo:
- prove dimostrative
- prove parcellari
Le prove dimostrative, di solito, costituiscono la fase finale dello sviluppo di una nuova tecnica agronomica e, pertanto, vengono condotte su scala aziendale, utilizzando i normali macchinari di un’azienda agraria e considerando tutta la variabilità tipica delle normali condizioni di coltivazione in pieno campo. Questi esperimenti, usualmente, vengono condotti su striscie di terreno (strip), usualmente di forma rettangolare e di dimensione adatta alle normali seminatrici e trebbiatrici aziendali.
Di solito il numero dei trattamenti è basso, spesso pari a due: la tecnica innovativa e quella usuale, con funzioni di controllo. Questi due trattamenti sono allocati a due strisce contigue che costituiscono un ‘blocco’, ripetuto tre o quattro volte, in modo da catturare la variabilità del campo. Per semplicità, considerando l’ampia dimensione delle strisce, la randomizzazione può essere omessa, cosi che il disegno assomiglia al tipo A3 nella Figura 1.4 (capitolo precedente). Un esempio di questo lay-out è riportato in Figura 2.1, dove si vedono quattro campi con due strisce ciascuno. In un campo, i trattamenti sono allocati a ciascuna delle due strisce.

Figura 2.1: Esempio di disegno sperimentale per una prova dimostrativa, con quattro campi, due strisce per campo e un diverso trattamento per striscia (giallo e bianco)
Gli esperimenti dimostrativi sono spesso ripetuti nello spazio e nel tempo, per ottenere informazioni più attendibili sulla validità della tecnica innovativa.
Le prove parcellari sono, invece, una via di mezzo tra le prove dimostrative e gli esperimenti di laboratorio: pur essendo in pieno campo, le parcelle di terreno sono sufficientemente piccole per consentire un elevato grado di precisione e di controllo (Figura 2.2 ). Ovviamente, questo elevato grado di controllo consente di ottenere produzioni che sono, mediamente, un 10-30% maggiori di quelle ottenibili su scala aziendale.

Figura 2.2: Una prova sperimentale in campo (Foto D. Alberati)
La dimensione delle parcelle viene scelta in modo da avere un numero di piante sufficientemente alto da essere rappresentativo. Per questo motivo le colture a bassa fittezza (es. mais) hanno sempre bisogno di parcelle più grandi che non quelle ad alta fittezza (es. frumento). La dimensione non deve tuttavia essere troppo elevata, in quanto si viene a determinare un incremento della variabilità del terreno e, di conseguenza, una diminuzione della precisione dell’esperimento. Per questo motivo, talvolta si preferisce diminuire la dimensione delle parcelle ed, avendo lo spazio sufficiente, aumentare il numero delle repliche. E’ poi importante tenere conto delle dimensioni delle macchine operatrici che verranno utilizzate per le pratiche colturali; in genere, la larghezza della parcella dovrebbe essere pari a un multiplo della larghezza di lavoro delle seminatrici e/o raccoglitrici e/o delle macchine per la distribuzione dei fitofarmaci.
Nello stabilire la dimensione delle parcelle, dovremo tener conto del fatto che la parte più delicata è il bordo, in quanto le piante che si trovano lungo di esso risentono di condizioni diverse dalle altre piante situate al centro della parcella (effetto bordo). Questo determina variabilità all’interno della parcella, che possiamo minimizzare raccogliendo solo la parte centrale. Si viene così a distinguere la superficie totale della parcella dalla superficie di raccolta (superficie utile), che può essere anche molto minore di quella totale.
Tenendo conto degli aspetti detti in precedenza, riteniamo che le colture ad elevata fittezza (frumento, cereali, erba medica…) dovrebbero avere parcelle di almeno 10-20 m2, mentre le colture a bassa fittezza (mais, girasole…) dovrebbero avere parcelle di almeno 20-40 m2, con riferimento alla superficie utile di raccolta.
Per quanto riguarda la forma delle parcelle, anche se il quadrato minimizzerebbe l’effetto bordo, perché, a parità di superficie, ha un perimetro più basso, nella pratica le parcelle sono sempre rettangolari, per facilitare l’esecuzione delle operazioni meccaniche.Come già detto, la larghezza dovrebbe essere pari ad un multiplo del fronte di lavoro delle macchine operatrici da impiegare.
2.7.3 Numero di repliche
Per gli esperimenti di pieno campo il numero di repliche oscilla tra tre e cinque; con meno repliche l’esperimento è inefficiente, mentre un numero più elevato di repliche può essere dannoso, in quanto aumenta la dimensione dell’esperimento e, con essa, la variabilità del campo. Inoltre, un numero alto di repliche aumenta i costi e i tempi di esecuzione dei rilievi. Il numero totale di parcella, alla fine, risulta dal prodotto tra il numero delle tesi sperimentali e il numero delle repliche.
2.7.4 La mappa di campo
Il disegno di un esperimento, di solito, è pianificato su una mappa. Un esempio è riportato in Figura 2.3, relativamente ad un esperimento sistemato su un appezzamento largo 30 metri e lungo 400 metri. In questo caso abbiamo disegnato otto file di parcelle in senso trasversale (8 x 2.25 m = 18 m di larghezza), e quattro parcelle in senso longitudinale. Intorno all’esperimento abbiamo sistemato una serie di parcelle addizionali, con lo scopo di ridurre l’effetto ‘bordo’. Vediamo in figura che la mappa riporta tutte le informazioni che consentono di collocare correttamente l’esperimento nello spazio ed, inoltre, che le parcelle sono tutte chiaramente identificate con un codice numerico.

Figura 2.3: Mappa di campo di un esperimento con 32 parcelle
2.7.5 Lay-out sperimentale
Abbiamo già parlato di come possa essere conveniente, nella pratica sperimentale, porre dei vincoli alla randomizzazione. A seconda di come poniamo questi vincoli, distinguiamo diversi disegni sperimentali, che descriveremo nei prossimi paragrafi.
2.7.5.1 Disegni completamente randomizzati
Per queste prove, le più semplici, la scelta dei soggetti da trattare è totalmente casuale, senza vincoli di sorta. Il vantaggio principale è la semplicità; lo svantaggio sta nel fatto che tutte le eventuali differenze e disomogeneità tra unità sperimentali restano non riconosciute ed entrano nella definizione della variabilità residua. Per questo, i disegno completamente randomizzati sono utilizzato soprattutto per le situazioni di buona uniformità ambientale e tra i soggetti.
Come esempio, mostriamo un disegno completamente randomizzato utilizzando le parcelle della figura 2.3, alle quali abbiamo allocato 8 trattamenti (da A ad H) con quattro repliche. Come si può notare, l’allocazione è completamente casuale (figura 2.4)

Figura 2.4: Esempio di uno schema sperimentale a randomizzazione completa
2.7.5.2 Disegni a blocchi randomizzati
Quando le unità sperimentali non sono totalmente omogenee, ma vi è una certa variabilità per una qualche caratteristiche rilevante, potremo dividere i soggetti in base a questa caratteristica, in tanti gruppi quante sono le repliche.
Ad esempio, nel caso dello schema in figura 2.4, se ammettiamo l’esistenza di un gradiente di fertilità crescente das sinistra verso destra, allora il trattamento H è stato avvantaggiato, perché tre delle quattro repliche si trovano nella parte destra, mentre il trattamento G è stato svantaggiato, per il motivo opposto.
Si può ottenere un disegno più efficiente se dividendo l’esperimento in quattro blocchi perpendicolari al gradiente di fertilità. Ad esempio il blocco 1 conterrà le parcelle 1, 9, 17, 25, 2, 10, 18 e 26, cioè le prime due colonne della mappa, con un numero di parcelle esattamente uguali al numero dei trattamenti. Il blocco 2 conterrà le colonne 3 e 4 e così via. Dato che il gradiente è trasversale, le parcelle di un stesso blocco saranno più omogenee che non parcelle su blocchi diversi. Dopo aver diviso la mappa in quattro blocchi di otto parcelle, potremo allocare gli otto trattamenti a random all’interno di ogni blocco (2.5)

Figura 2.5: Esempio di uno schema sperimentale a blocchi randomizzati
Un disegno a blocchi randomizzati non è solo tipico della sperimentazione di campo. Ad esempio, volendo determinare la contaminazione da micotossine nelle confezioni di datteri, a seconda della modalità di confezionamento (es. carta, busta di plastica, scatola di plastica perforata), si può sospettare che il supermercato nel quale le confezioni vengono vendute potrebbe avere un certo effetto, legato alle modalità di conservazione. Per cui, invece che prelevare trenta confezioni (dieci per metodo) a caso nei supermercati di una città, scegliamo dieci supermercati e, in ognuno, prendiamo una confezione per tipo. In questo caso, il supermercato fa da blocco.
Il vantaggio del disegno a blocchi randomizzati sta nel fatto che ci permetto di utilizzare soggetti sperimentali con una più bassa omogeneità iniziale, aspetto importante quando il numero di unità sperimentali richieste comincia ad essere elevato. Infatti, le differenze tra soggetti sperimentali, almeno in parte, possono essere spiegate attraverso l’appartenenza ad un determinato gruppo (blocco) e possono quindi essere scorporate dal calcolo della variabilità residua.
2.7.5.3 Disegni a quadrato latino
In questo caso, le unità sperimentali presentano due ‘gradienti’, cioè vi sono differenze legate a due elementi importanti, oltre al trattamento sperimentale. La Figura 2.6 mostra un esperimento con quattro trattamenti e altrettante repliche, nel quale ogni trattamento si trova in tutte le righe e tutte le colonne, in modo da poter considerare eventuali gradienti di fertilità da destra verso sinistra e dall’alto verso il basso. La figura mostra anche perché si parli di quadrato latino: in effetti il numero di righe è uguale al numero di colonne, secondo una griglia quadrata. Qualcuno di voi riconoscerà in questo schema i principi di fondo del Sudoku.
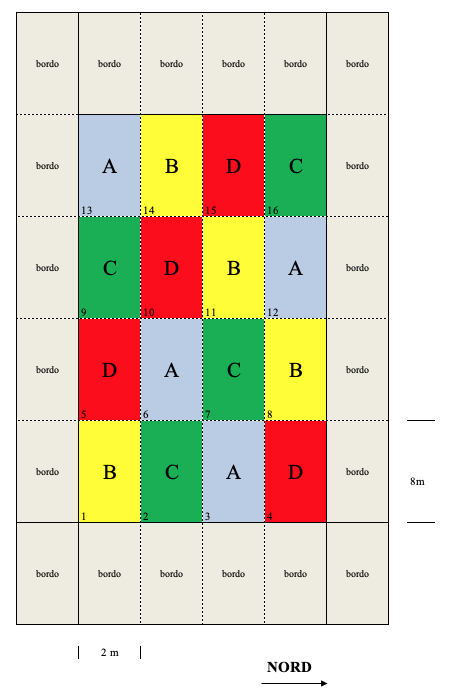
Figura 2.6: Esempio di un disegno sperimentale a quadrato latino, con quattro trattamenti (A, B, C e D) ed altrettante repliche. I colri aiutano ad identificare i quattro trattamenti e la posizione delle rispettive parcelle
I disegni a quadrato latino non sono solo utili per gli esperimenti di pieno campo; ad esempio, se un certo oggetto richiede un solo operatore per essere costruito e vogliamo confrontare quattro metodi costruttivi, possiamo pianificare un esperimento dove l’unità sperimentale è il lavoratore. Volendo lavorare con quattro repliche, avremmo bisogno di sedici operatori per disegnare un esperimento completamente randomizzato. Possiamo tuttavia considerare che un operatore, in quattro turni successivi, può operare con tutti e quattro i metodi. Quindi possiamo disegnare un esperimento in cui il turno fa da unità sperimentale e l’operatore fa da blocco (esperimento a blocchi randomizzati).
Tuttavia, in ogni blocco (operatore) vi è un gradiente, nel senso che i turni successivi al primo sono via via meno efficienti, perché l’operatore accumula stanchezza. Per tener conto di questo, potremmo lasciare all’operatore un congruo periodo di tempo tra un turno e l’altro. Oppure, potremmo introdurre un vincolo ulteriore, per ogni operatore, randomizzando i quattro metodi tra i turni, in modo che ogni metodo, in operatori diversi, capiti in tutti i turni. In sostanza, l’operatore fa da blocco, perché in esso sono contenuti tutti i metodi. Ma anche il turno (per tutti gli operatori) fa da blocco, in quanto in esso sono ancora contenuti tutti i metodi. Proviamo a schematizzare, nella figura seguente (2.7 ).
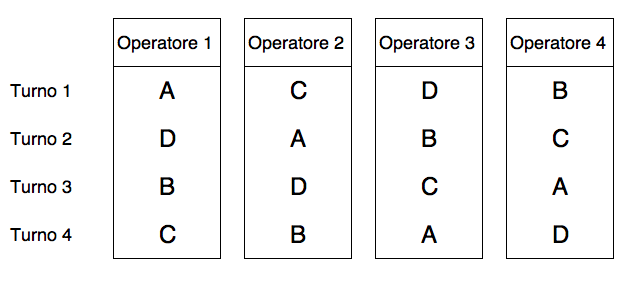
Figura 2.7: Allocazione di quattro metodi di lavoro (A, B, C e D), tra quattro operatori, in quattro turni, seguendo uno schema a quadrato latino
Il disegno a quadrato latino è utile, perché possiamo dar conto sia delle differenza tra righe (es. turni), che delle differenze tra colonne (es. operatori), in modo da ridurre al minimo possibile la variabilità inspiegabile. Lo svantaggio sta nel fatto che, dovendo avere tante repliche quanti sono i trattamenti, è utilizzabile solo per esperimenti abbastanza piccoli.
2.7.5.4 Disegni a split-plot
Gli esperimenti fattoriali possono essere disegnati con uno schema a randomizzazione completa o a blocchi randomizzati, allocando alle unità sperimentali tutte le combinazioni dei fattori in studio. Per esempio, consideriamo un esperimento per confrontare tre tipi di lavorazioni del terreno (minimum tillage = MIN; aratura superficiale = SP; aratura profonda = DP) e due tipi di controllo chimico delle piante infestanti (a pieno campo = TOT; lungo la fila = PARZ). Se vogliamo fare quattro repliche, i sei trattamenti sperimentali (MIN-TOT, SP-TOT, DP-TOT, MIN-PARZ, SP-PARZ and DP-PARZ) possono essere allocati alle 24 parcelle secondo uno schema a blocchi randomizzati, come indicato in Figura 2.8. In questo caso è necessario lasciare un ampio spazio tra le parcelle, in modo da permettere la circolazione delle macchine operatrici per la lavorazione ed, inoltre, le parcelle debbono essere grandi, per consentire una buona esecuzione dell’aratura.
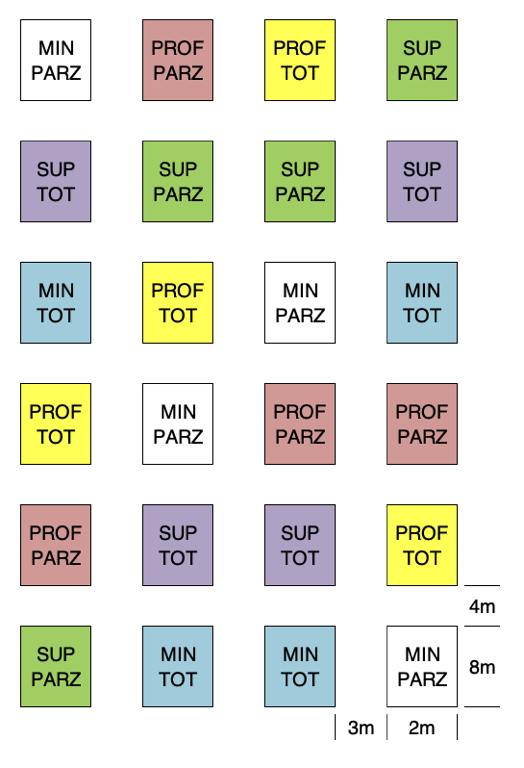
Figura 2.8: Mappa di campo per un esperimento fattoriale con due fattori, disegnato a blocchi randomizzati
Dato che il trattamento di diserbo non richiede parcelle altrettanto grosse, potremmo pensare di suddividere ogni parcella in due sub-parcelle, sulle quali allocare il trattamento di diserbo (disegno a parcella suddivisa o split-plot). Un esempio è riportato in Figura 2.9, dove possiamo osservare che le lavorazioni sono allocate su 12 parcelle principali (mainplots), secondo uno schema a blocchi randomizzati, mentre i trattamenti di diserbo sono allocati in modo randomizzato sulle due subplot in ogni mainplot. Tecnicamente, diciamo che la lavorazione è il fattore di primo ordine, mentre il diserbo chimico è il fattore di secondo ordine. Notiamo che l’esperimento diviene più piccolo e quindi più preciso.
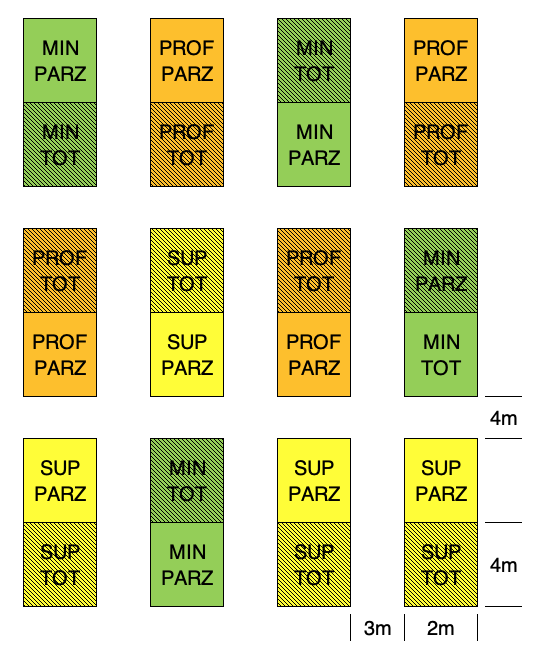
Figura 2.9: Stesso esperimento descritto nella figura precedente, ma disegnato con uno schema a split-plot.
In generale, un disegno a split-plot può rendersi necessario per i seguenti motivi:
- un fattore sperimentale richiede parcelle più grandi dell’altro. Di conseguenza si disegna l’esperimento per il fattore che richiede parcelle più grandi, che vengono poi suddivise per accomodare l’altro fattore sperimentale.
- Uno dei due fattori sperimentali è più ‘difficile’ da assegnare rispetto all’altro e quindi è preferibile manipolare congiuntamente tutto il gruppo di unità sperimentali che deve riceverlo. Ad esempio, se vogliamo misurare la resistenza alla corrosione di barre d’acciaio con diversi rivestimenti e forgiate a diverse temperature, è evidente che la gestione della temperatura nella fornace è piuttosto complessa, perché richiede tempi lunghi per essere cambiata e raggiungere un nuovo equilibrio. Invece che preparare una fornace per ogni rivestimento (manipolazione indipendente delle unità sperimentali), si mettono nella stessa fornace tutte le unità sperimentali con i diversi rivestimenti. Una situazione analoga si può avere se vogliamo provare diverse miscele per torte (con vari ingredienti), e diversi tempi di cottura; dato che non è agevole preparare una miscela diversa per ogni tempo di cottura, potremmo preparare una miscela tutta insieme, per poi suddividerla tra i diversi tempi di cottura.
- La disponibilità di unità sperimentali è limitata, come accade con gli armadi climatici, che vengono impostati a diversa temperatura e all’interno delle quali vengono randomizzate le tesi sperimentali di secondo ordine.
Un’importante conseguenza dei disegni a split-plot è che ogni mainplot funge da replica per il fattore sperimentale di secondo ordine. In effetti, se guardiamo alla Figura 2.9, possiamo osservare che ci sono quattro repliche per ogni lavorazione, ma 12 repliche per ogni tipo di diserbo chimico. Di conseguenza, l’effetto del fattore sperimentale di secondo ordine è stimato con maggior precisione.
2.7.5.5 Disegni a strip-plot
In alcune circostanze, soprattutto nelle prove di diserbo chimico, potrebbe trovare applicazione un altro tipo di schema sperimentale, nel quale ogni blocco viene diviso in tante righe quanti sono i livelli di un fattore sperimentale e tante colonne quanti sono i livelli dell’altro. In questo modo, il primo trattamento sperimentale viene applicato a tutte le parcelle di una riga e l’altro trattamento a tutte le parcelle di una colonna. Ovviamente, l’allocazione alle righe e alle colonne è casuale e cambia in ogni blocco.
Questo disegno è detto strip-plot ed è molto comodo perché consente di lavorare velocemente. Se consideriamo il caso studio precedente, un disegno a strip-plot potrebbe essere immaginato come in Figura 2.10.
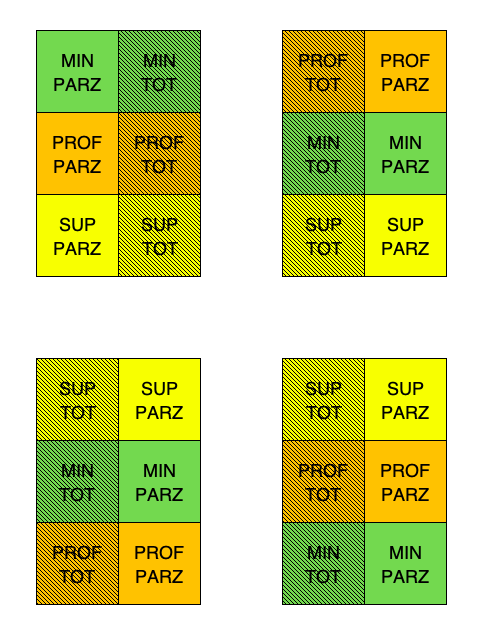
Figura 2.10: Esempio di un disegno a strip-plot per il dataset ‘beet.csv’, che prevede tre livelli di lavorazione e due livelli di diserbo chimico
2.8 Altre letture
- Cochran, W.G., Cox, G.M., 1950. Experimental design. John Wiley & Sons, Inc., Books.
- LeClerg, E.L., Leonard, W.H., Clark, A.G., 1962. Field Plot Technique. Burgess Publishing Company, Books.
2.9 Domande ed esercizi
2.9.1 Domanda 1
Quali sono le caratteristiche fondamentali di un esperimento scientifico, perché possa essere ritenuto valido?
2.9.3 Domanda 3
Illustrare brevemente la differenza tra errori casuali e sistematici. In presenza di quale dei due è possibile ottenere risultati scientifici validi?
2.9.5 Domanda 5
Cosa è il confounding e come può rendere distorti i risultati di un esperimento scientifico?
2.9.9 Domanda 9
Quali sono le caratteristiche principali degli esperimenti a randomizzazione completa, blocchi randomizzati e quadrato latino?
2.9.12 Domanda 13
Illustrare e discutere le caratteristiche fondamentali delle ‘parcelle’ (forma, dimensioni, numero …)
2.9.13 Esercizio 1
Vi è stata affidata una prova sperimentale per la taratura agronomica di un nuovo diserbante appartenente al gruppo chimico delle solfoniluree (AGRISULFURON), utilizzabile alla dose presumibile di 20 g/ha, per il diserbo di post-emergenza del mais. Gli obiettivi della prova sono:
- Valutare se è opportuno un certo aggiustamento della dose (incremento/diminuzione)
- Valutare se è opportuna l’aggiunta di un bagnante non-ionico
- Valutare se è opportuno splittare la dose di 20 g/ha in due distribuzioni
- Valutare l’efficacia del nuovo diserbante con gli opportuni controlli (testimoni)
Coerentemente con questi obiettivi, scrivere un protocollo sperimentale sufficientemente dettagliato (una pagina) ed aggiungere la mappa di campo della prova. Considerare che abbiamo a disposizione un campo lungo 80 metri e largo 26 metri, in direzione Nord-Sud, lavorato nel senso della lunghezza e con un gradiente di ‘fertilità’ trasversale, nel senso della larghezza.
2.9.14 Esercizio 2
Dovete progettare una prova sperimentale per valutare i possibili effetti dell’epoca di semina (autunnale oppure primaverile) su sette varietà di favino (che etichetteremo con le lettere da A a G). Progettare un esperimento di pieno campo, decidendo il numero di repliche ed il lay-out sperimentale. Redigere la mappa di campo ed allocare i trattamenti, in base al lay-out prescelto. Aggiungere alla mappa di campo tutti i dettagli necessari (dimensioni delle parcelle, localizzazione ed orientamento dell’esperimento). Considerate che abbiamo a disposizione un campo lungo 60 metri e largo 40 metri, in direzione Est-Ovest, lavorato nel senso della lunghezza e con un gradiente di ‘fertilità’ longitudinale.
2.9.15 Esercizio 3
Illustrate il disegno sperimentale che adottereste per organizzare una prova che metta a confronto quattro concimi azotati (urea, solfato ammonico, nitrato di calcio e nitrato di sodio) e un testimone non concimato su barbabietola da zucchero. Motivate opportunamente le vostre scelte. Considerate che abbiamo a disposizione un campo lungo 50 metri e largo 30 metri, in direzione Est-Ovest, lavorato nel senso della lunghezza e con due gradienti di ‘fertilità’, longitudinale e trasversale.
2.9.16 Esercizio 4
Descrivete lo schema sperimentale che adottereste per organizzare un esperimento di confronto tra quattro dosi di un diserbate per il frumento, utilizzato con e senza un coadiuvante. Motivate opportunamente le vostre scelte. Considerate che abbiamo a disposizione un campo lungo 50 metri e largo 20 metri, in direzione Est-Ovest, lavorato nel senso della lunghezza e con due gradienti di ‘fertilità’, longitudinale e trasversale.
2.9.17 Esercizio 5
Descrivete lo schema sperimentale che utilizzereste per organizzare una prova su pomodoro da industria, per la valutazione dell’effetto di tre livelli di concimazione azotata (0, 80 e 160 kg/ha) e tre tipologie di interventi irrigui (asciutto, basso volume irriguo, alto volume irriguo). Motivate opportunamente le vostre scelte. Considerate che abbiamo a disposizione un campo lungo 100 metri e largo 25 metri, in direzione Est-Ovest, lavorato nel senso della lunghezza e con un gradiente di fertilità longitudinale.