Capitolo 11 Modelli ANOVA a due vie
11.1 Il concetto di ’interazione’
In alcuni casi potremmo essere interessati ad organizzare un esperimento per valutare l’effetto di due fattori sperimentali combinati (ad esempio la lavorazione del terreno ed il diserbo chimico), in modo da mettere in evidenza possibili “interazioni.” Con questo termine intendiamo il fenomeno per cui l’effetto di un fattore (ad es. la lavorazione) cambia a seconda del livello dell’altro fattore (il diserbo chimico). Ad esempio, osserviamo la Tabella 11.1, dove sono risportate le medie per le quattro combinazioni risultati da un esperimento con due fattori (A e B) a due livelli ciascuno (A1 e A2, oltre a B1 e B2). Le medie per le quattro combinazioni sono dette ‘medie di cella,’ mentre le medie delle medie, ad esempio la media delle due combinazioni che contengono A1, sono dette ‘medie marginali,’ appunto perché si trovano ai margini della tabella.
Osserviamo che, ad esempio, A2 da un risultato più elevato di A1, quando il secondo fattore sperimentale è B1, mentre la graduatoria è invertita con B2.
| B1 | B2 | Media | |
|---|---|---|---|
| A1 | 10.0 | 14.0 | 12 |
| A2 | 15.0 | 9.0 | 12 |
| Media | 12.5 | 11.5 | 12 |
La presenza di interazione può influenzare notevolmente l’interpretazione dei risultati. Infatti, se guardassimo solo alle medie marginali del fattore A, saremmo portati a concludere che i due livelli A1 ed A2 forniscono, più o meno, gli stessi risultati. In realtà questo è falso, in quanto A1 ed A2 forniscono risultati molto diversi, ma le differenze sono di segno opposto, a seconda del livello di B.
11.2 Tipi di interazione
In genere, abbiamo due tipi di interazione: quella in cui cambia la graduatoria tra i trattamenti (interazione crossover) e quella in cui vi è solo una modifica dell’entità dell’effetto (interazione semplice o non-crossover). I due tipi di interazione sono esemplificati in Figura 11.1, che mostra, nel grafico di destra, gli stessi dati riportati nella Tabella 11.1.
Concentriamoci un attimo sul grafico di sinistra e consideriamo la prima combinazione in ordine alfabetico (A1B1): per questa, la media è pari a 10. Se passiamo da A1 ad A2, fermo restando B1, l’incremento è + 4. Se invece passiamo da B1 a B2, fermo restando A1, l’incremento è + 5. Quindi l’effetto di A è pari a +4 e l’effetto di B è pari a +5 e i due effetti sono puramente addittivi. Infatti, ad esempio, A2B2 è pari a 10 + 4 + 5 = 19. Questa situazione riflette la totale mancanze di interazione.
Al contrario, nel grafico centrale vediamo che il risultato di A2B2 non può essere ottenuto per semplice somma di effetti, perché, a fronte di un risultato atteso pari a 19 otteniamo invece 16. Evidentemente, vi è qualcosa in questa combinazione che altera l’effetto congiunto di A e B. Questo qualcosa può essere quantificato con il valore - 3, così che la media A2B2 è pari a 10 + 4 + 5 - 3 = 16. Il valore -3 rappresenta la mancanza di additività o interazione. Si tratta di interazione semplice in quanto essa non altera la graduatoria dei trattamenti: A2 è sempre meglio di A1 e B2 è sempre meglio di B1, anche se gli effetti non sono quelli previsti.
Nel grafico di sinistra la situazione è analoga, ma più estrema: l’effetto dell’interazione è -10 e comporta un’inversione della graduatoria, già menzionata per la Tabella Tabella 11.1.
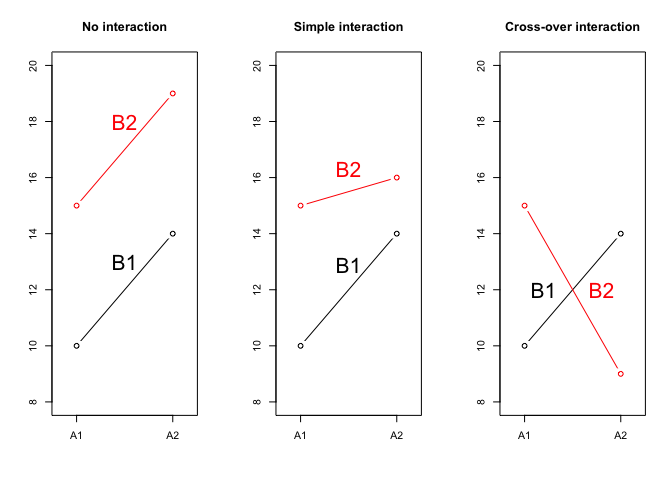
Figure 11.1: Esempi di interazione tra fattori sperimentali
Da un punto di vista dell’interpretazione dei risultati, l’interazione cross-over è particolarmente importante, perché non consente di raggiungere conclusioni generali per i due fattori sperimentali presi indipendentemente l’uno dall’altro.
11.3 Caso-studio: interazione tra lavorazioni e diserbo chimico
Un ricercatore ha organizzato un esperimento fattoriale a blocchi randomizzati, dove ha valutato l’effetto di tre tipi di lavorazione del terreno (lavorazione minima = MIN; aratura superficiale = SUP; aratura profonda = PROF) e di due tipi di diserbo chimico (a pieno campo = TOT; localizzato sulla fila della coltura = PARZ). L’ipotesi scientifica è che, in caso di diserbo localizzato, il rovesciamento del terreno prodotto dall’aratura sia fondamentale, in quanto sotterra i semi prodotti dalle piante infestanti, impedendone l’emergenza nella coltura successiva e rendendo quindi necessario il diserbo a tutta superficie. La mappa di campo è presentata in Figura 11.2; dobbiamo notare lo spazio lasciato tra una parcella e l’altra, per permettere l’uso e la circolazione delle macchine per la lavorazione.
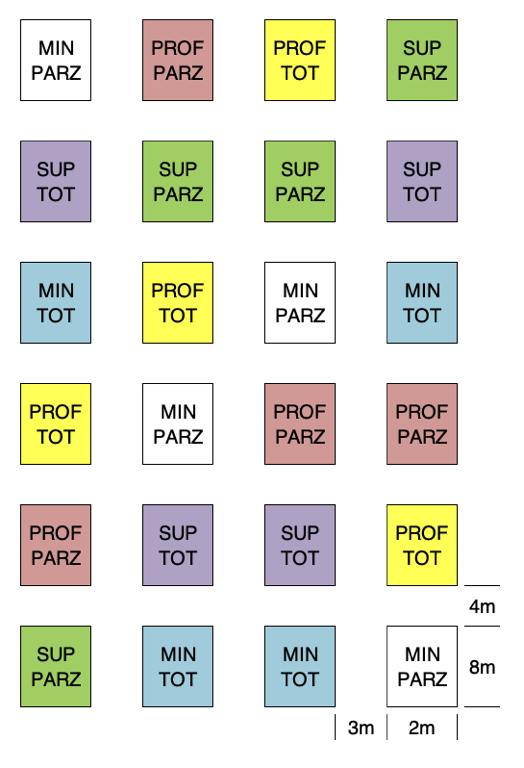
Figure 11.2: Mappa dell’esperimento fattoriale a blocchi randomizzati
In totale, l’esperimento include sei tesi (le sei possibili combinazioni tra i due fattori sperimentali) e quattro repliche per un totale di 24 parcelle. Come consuetudine in pieno campo, l’esperimento è organizzato a blocchi randomizzati e le sei tesi sperimentali sono allocate a caso all’interno di ciascun blocco.
I risultati ottenuti con questo esperimento sono disponibili nel file ‘beet.csv,’ che può essere aperto direttamente da gitHub, con il codice sottostante.
path1 <- "https://raw.githubusercontent.com/OnofriAndreaPG/"
path2 <- "aomisc/master/data/"
name <- "beet.csv"
pathName <- paste(path1, path2, name, sep = "")
dataset <- read.csv(pathName, header=T)
head(dataset)
## Lavorazione Diserbo Blocco Prod
## 1 MIN tot 1 11.614
## 2 MIN tot 2 9.283
## 3 MIN tot 3 7.019
## 4 MIN tot 4 8.015
## 5 MIN parz 1 5.117
## 6 MIN parz 2 4.30611.4 Definizione del modello lineare
I risultati di questo esperimento sono determinati da quattro elementi ‘deterministici’:
- l’effetto del blocco
- l’effetto della lavorazione
- l’effetto del diserbo chimico
- l’interazione ‘lavorazione \(\times\) diserbo’
Un modello lineare con questi quattro effetti potrebbe essere scritto:
\[Y_{ijk} = \mu + \gamma_k + \alpha_i + \beta_j + \alpha\beta_{ij} + \varepsilon_{ijk}\]
dove \(\gamma\) è l’effetto del blocco \(k\), \(\alpha\) è l’effetto della lavorazione \(i\), \(\beta\) è l’effetto del diserbo \(j\), \(\alpha\beta\) è l’effetto dell’interazione per la specifica combinazione della lavorazione \(i\) e del diserbo \(j\). Oltre a questi elementi ‘deterministici’ i risultati sono influenzati dall’elemento stocastico \(\varepsilon\), associato ad ogni osservazione, che si assume normalmente distribuito con media 0 e deviazione standard pari a \(\sigma\).
11.5 Stima dei parametri
Per rendere ‘stimabili’ i parametri, poniamo un vincolo sul trattamento, per cui \(\gamma_1 = 0\), \(\alpha_1 = 0\) (primo livello in ordine alfabetico, cioè MIN), \(\beta_1 = 0\) (primo livello in ordine alfabetico, cioè PARZ). Per quanto riguarda l’interazione \(\alpha\beta\), abbiamo 6 combinazioni possibili tra il primo e il secondo fattore (MIN - TOT, MIN - PARZ, SUP - TOT, SUP - PARZ, PROF - TOT, PROF - PARZ); di queste, dobbiamo vincolare tutte le combinazioni che contengono il primo livello in ordine alfabetico per uno dei due fattori (MIN - TOT, MIN - PARZ, SUP - PARZ, PROF - PARZ, corrispondenti ad \(\alpha\beta_{1,1}\) = \(\alpha\beta_{1,2}\) = \(\alpha\beta_{2,1}\) = \(\alpha\beta_{3,1}\) = 0).
Con questi vincoli, \(\mu\) è il valore atteso per la parcella localizzata nel primo blocco e trattata con il primo livello in ordine alfabetico per tutti i fattori sperimentali (\(\bar{Y}_{111}\)). I tre valori \(\gamma\) rappresentano rispettivamente \(\gamma_2 = \bar{Y}_{112} - \bar{Y}_{111}\), \(\gamma_3 = \bar{Y}_{113} - \bar{Y}_{111}\) e \(\gamma_4 = \bar{Y}_{114} - \bar{Y}_{111}\). Abbiamo invece che \(\alpha_2 = \bar{Y}_{211} - \bar{Y}_{111}\) e \(\alpha_3 = \bar{Y}_{311} - \bar{Y}_{111}\), mentre \(\beta_2 = \bar{Y}_{121} - \bar{Y}_{111}\) e \(\beta_3 = \bar{Y}_{131} - \bar{Y}_{111}\). Per quanto riguarda l’interazione, abbiamo due soli parametri da stimare, per i quali possiamo fare le seguenti considerazioni:
\[\bar{Y}_{111} = \mu + \alpha_1 + \beta_1 + \alpha\beta_{11} = \mu\]
\[\bar{Y}_{221} = \mu + \alpha_2 + \beta_2 + \alpha\beta_{22}\]
quindi:
\[\bar{Y}_{221} - \bar{Y}_{111} = \alpha_2 + \beta_2 + \alpha\beta_{22}\]
da cui:
\[\alpha\beta_{22} = \bar{Y}_{221} - \bar{Y}_{111} - \alpha_2 - \beta_2\]
Analogamente:
\[\alpha\beta_{32} = \bar{Y}_{321} - \bar{Y}_{111} - \alpha_3 - \beta_2\]
Vediamo che, quando i modelli divengono appena appena più complessi, la parametrizzazione con vincolo sulla somma diventa abbastanza controintuitiva, e, inoltre, la stima dei parametri diventa abbastanza difficile da fare a mano. Al contrario, quest’operazione è piuttosto semplice e intuitiva quando si impieghi il vincolo sulla somma. Per chi volesse approfondire, ci sono alcune ulteriori informazioni in fondo al capitolo.
In questa sede, per la stima dei parametri ci affidiamo ad R e al metodo dei minimi quadrati, confidando che le informazioni precedenti possano essere utili a capire l’output del programma.
mod <- lm(Prod ~ factor(Blocco) + Lavorazione + Diserbo +
Lavorazione:Diserbo, data=dataset)
summary(mod)
##
## Call:
## lm(formula = Prod ~ factor(Blocco) + Lavorazione + Diserbo +
## Lavorazione:Diserbo, data = dataset)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.78329 -0.78754 -0.04437 0.31117 3.12546
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 6.6422 0.8376 7.930 9.59e-07 ***
## factor(Blocco)2 -1.0380 0.7897 -1.314 0.208431
## factor(Blocco)3 -0.8277 0.7897 -1.048 0.311179
## factor(Blocco)4 -0.7232 0.7897 -0.916 0.374267
## LavorazionePROF 4.6338 0.9671 4.791 0.000238 ***
## LavorazioneSUP 2.4803 0.9671 2.565 0.021568 *
## Diserbotot 2.9878 0.9671 3.089 0.007480 **
## LavorazionePROF:Diserbotot -4.4098 1.3677 -3.224 0.005677 **
## LavorazioneSUP:Diserbotot -2.3218 1.3677 -1.698 0.110246
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.368 on 15 degrees of freedom
## Multiple R-squared: 0.641, Adjusted R-squared: 0.4495
## F-statistic: 3.348 on 8 and 15 DF, p-value: 0.02095Una volta stimati i parametri, possiamo individuare la devianza residua, come somma dei quadrati degli scarti tra i valori attesi e i valori osservati. I residui, in R, possono essere ottenuti con la funzione ‘residuals().’
RSS <- sum( residuals(mod)^2 )
RSS
## [1] 28.06087Consideriamo che la devianza del residuo ha un numero di gradi di libertà pari alla differenza tra il numero dei dati è il numero dei parametri stimati (24 - 9 = 15). Di conseguenza, possiamo stimare \(\sigma\), come:
sqrt(RSS/15)
## [1] 1.367744o, più velocemente, con l’apposito estrattore:
summary(mod)$sigma
## [1] 1.36774411.6 Verifica delle assunzioni di base
Dobbiamo quindi procedere con la verifica delle assunzioni di base, attraverso l’analisi grafica dei residui, come indicato in un capitolo precedente. Il grafico dei residui contro i valori attesi ed il QQ-plot sono riportati in Figura 11.3.
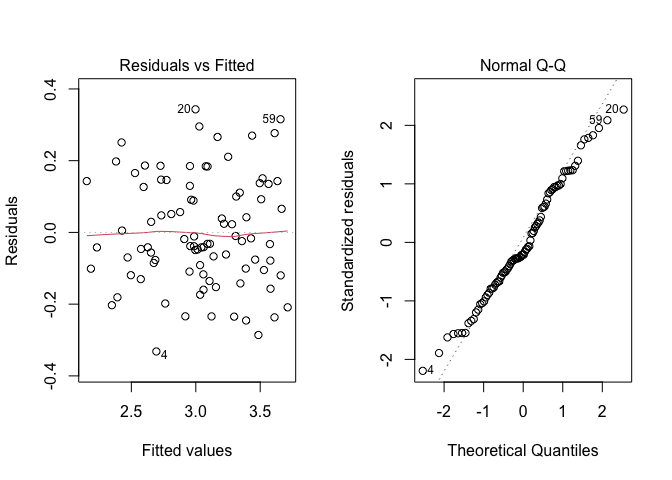
Figure 11.3: Analisi grafica dei residui con R
Il grafico dei residui mostra un sospetto outlier (il settimo dato). Tuttavia, non abbiamo memoria di errori durante la sperimentazione e a parte questo outlier, non paiono esserci problemi di omogeneità delle varianze. Pertanto, decidiamo di ignorare questo potenziale dato aberrante e proseguire nell’analisi, in quanto non sussistono particolare elementi che facciano sospettare qualche patologia dei dati più o meno rilevante.
11.7 Scomposizione delle varianze
Se dovessimo scomporre le varianze manualmente, potremmo costruire il modello in modo sequenziale, il che è totalmente corretto con i disegni bilanciati come il nostro.
mod0 <- lm(Prod ~ 1, data=dataset)
mod1 <- lm(Prod ~ factor(Blocco), data=dataset)
mod2 <- lm(Prod ~ factor(Blocco) + Lavorazione, data=dataset)
mod3 <- lm(Prod ~ factor(Blocco) + Lavorazione + Diserbo,
data=dataset)
mod4 <- lm(Prod ~ factor(Blocco) + Lavorazione + Diserbo +
Lavorazione:Diserbo, data=dataset)
RSS0 <- deviance(mod0)
RSS1 <- deviance(mod1)
RSS2 <- deviance(mod2)
RSS3 <- deviance(mod3)
RSS4 <- deviance(mod4)Vediamo che il modello nullo ha un residuo pari a 78.161505, mentre il il modello con il solo effetto del blocco ha un residuo più basso e pari 74.5019152. Evidentemente, l’introduzione del blocco ha migliorato la capacità descrittiva del modello e l’effetto di questa variabile può essere quantificato con la differenza tra le due devianze:
RSS0 - RSS1
## [1] 3.65959Analogamente, l’effetto della lavorazione (devianza della lavorazione) è dato da:
RSS1 - RSS2
## [1] 23.65647Ovviamente, possiamo evitare di procedere in questo modo, sfruttando le funzionalità di R e, in particolare, la funzione ‘anova()’:
anova(mod)
## Analysis of Variance Table
##
## Response: Prod
## Df Sum Sq Mean Sq F value Pr(>F)
## factor(Blocco) 3 3.6596 1.2199 0.6521 0.59389
## Lavorazione 2 23.6565 11.8282 6.3228 0.01020 *
## Diserbo 1 3.3205 3.3205 1.7750 0.20266
## Lavorazione:Diserbo 2 19.4641 9.7321 5.2023 0.01922 *
## Residuals 15 28.0609 1.8707
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1La quantificazione dei gradi di libertà dovrebbe essere chiara; aggiungiamo solo che, in generale, i gradi di libertà di un’interazione sono pari al prodotto tra i gradi di libertà degli effetti da cui essa è composta e coincidono con il numero di parametri stimati (in questo caso due).
Nel leggere una tabella ANOVA a due (o più) vie, è fondamentale procedere dal basso verso l’alto, in quanto la presenza di un’interazione significativa rende non-informative sia le significanze degli effetti principali, sia le medie marginali. Infatti, come abbiamo visto all’inizio, vi possono essere casi in cui le medie marginali sono simili, ma ciò è dovuto alla presenza di un’interazione cross-over. In questo caso, essendo significativa l’interazione tra lavorazione e diserbo, dovremo considerare e confrontare le sei medie per le combinazioni tra questi due fattori sperimentali.
11.8 Medie marginali attese
Può essere interessante vedere come si costruiscono le medie marginale attese, con un attento uso dei contrasti. Ad esempio, le medie attese per le sei combinazioni ‘lavorazione x diserbo’ possono essere ottenute considerando che \(\mu\) è il valore atteso per MIN-PARZ nel primo blocco, mentre \(\mu + \gamma_2\) è il valore atteso per MIN-PARZ nel secondo blocco, e così via. Di conseguenza, la media per la combinazione MIN-PARZ sarà pari a:
\[ \frac{\mu + (\mu + \gamma_2) + (\mu + \gamma_3) + (\mu + \gamma_4)}{4} = \mu + \frac{1}{4}\gamma_2 + \frac{1}{4}\gamma_3 + \frac{1}{4}\gamma_4\]
I parametri stimati sono derivabili con la funzione ‘coef(),’ quindi la combinazione lineare sopra indicata può essere ottenuta come segue:
coef(mod)[1] + 1/4*coef(mod)[2] + 1/4*coef(mod)[3] + 1/4*coef(mod)[4]
## (Intercept)
## 5.995Ovviamente, è più conveniente costruire una vettore con i coefficienti del contrasto, e moltiplicare per il vettore dei parametri stimati, come segue:
k1 <- c(1, 1/4, 1/4, 1/4, 0, 0, 0, 0, 0)
sum( coef(mod) * k1 )
## [1] 5.995Le altre medie, possono essere ottenute analogamente.
k2 <- c(1, 1/4, 1/4, 1/4, 1, 0, 0, 0, 0) #PROF - PARZ
k3 <- c(1, 1/4, 1/4, 1/4, 0, 1, 0, 0, 0) #SUP - PARZ
k4 <- c(1, 1/4, 1/4, 1/4, 0, 0, 1, 0, 0) #MIN - TOT
k5 <- c(1, 1/4, 1/4, 1/4, 1, 0, 1, 1, 0) #PROF - TOT
k6 <- c(1, 1/4, 1/4, 1/4, 0, 1, 1, 0, 1) #SUP - TOT
sum( coef(mod) * k2 )
## [1] 10.62875
sum( coef(mod) * k3 )
## [1] 8.47525
sum( coef(mod) * k4 )
## [1] 8.98275
sum( coef(mod) * k5 )
## [1] 9.20675
sum( coef(mod) * k6 )
## [1] 9.14125Anche se è comodo conoscere come eseguire queste operazioni, da un punto di vista pratico è certamente più comodo utilizzare la funzione ‘emmeans()’ del package ‘emmeans,’ di cui daremo un esempio tra poco.
11.9 Calcolo degli errori standard (SEM e SED)
Tutte le quantità ottenute più sopra sono state calcolate come combinazioni lineari di parametri del modello. Di conseguenza, le loro varianze sono derivabili con la legge di propagazione degli errori. In questo caso semplice (dati bilanciati), possiamo utilizzare la usuale formula per la quale l’errore standard di una media si ottiene dalla radice quadrata del rapporto tra la varianza del residuo e il numero delle repliche.
Tuttavia, anche se la varianza del residuo è la stessa, il numero di dati che concorrono a formare le medie è diverso (diverso numero di repliche). Infatti, le medie di ogni combinazione ‘diserbo x lavorazione’ hanno un numero di repliche pari a quattro, mentre le lavorazioni hanno un numero di repliche pari a quattro per il numero dei livelli di diserbo (cioè 8). Il diserbo ha invece un numero di repliche pari a quattro per il numero dei livelli di lavorazione (cioè 12).
Di conseguenza:
\[SEM_A = \sqrt{\frac{1.87}{4 \cdot 2}} = 0.483\]
\[SEM_B = \sqrt{\frac{1.87}{4 \cdot 3}} = 0.395\]
\[SEM_{AB} = \sqrt{\frac{1.87}{4}} = 0.684\]
Possiamo notare che le medie degli effetti principali, grazie al numero di repliche più elevato, sono stimate con maggiore precisione delle medie delle combinazioni.
Per quanto riguarda gli errori standard delle differenze tra medie (SED), questi si ottengono dai SEM, moltiplicandoli per \(\sqrt(2)\), come usuale. Dai SED, posso calcolare le Minime Differenze Significative, moltiplicandoli per il valore di t di Student, per il 5% di probabilità (test a due code) e 15 gradi di libertà, pari a 2.131.
Dato che l’interazione è significativa, posso fare i confronti multipli solo tra le medie delle combinazioni ‘diserbo x lavorazione,’ dato che confrontare le medie degli effetti principali potrebbe portare a risultati poco attendibili, per i motivi precedentemente esposti.
11.10 Medie marginali attese e confronti multipli con R
Per ottenere medie, confronti multipli o altre analisi routinarie, possiamo utilizzare il package ‘emmeans.’ Il codice sottostante calcola le medie per le combinazioni ‘lavorazione x diserbo’ e confronta i diserbi a parità di lavorazione.
library(emmeans)
medie <- emmeans(mod, ~Diserbo|Lavorazione)
multcomp::cld(medie, adjust="none", Letters=LETTERS)
## Lavorazione = MIN:
## Diserbo emmean SE df lower.CL upper.CL .group
## parz 6.00 0.684 15 4.54 7.45 A
## tot 8.98 0.684 15 7.53 10.44 B
##
## Lavorazione = PROF:
## Diserbo emmean SE df lower.CL upper.CL .group
## tot 9.21 0.684 15 7.75 10.66 A
## parz 10.63 0.684 15 9.17 12.09 A
##
## Lavorazione = SUP:
## Diserbo emmean SE df lower.CL upper.CL .group
## parz 8.48 0.684 15 7.02 9.93 A
## tot 9.14 0.684 15 7.68 10.60 A
##
## Results are averaged over the levels of: Blocco
## Confidence level used: 0.95
## significance level used: alpha = 0.05Se volessimo confrontare le lavorazioni a parità di diserbo o tutte le combinazioni dovremmo utilizzare codice leggermente diverso:
medie <- emmeans(mod, ~Lavorazione|Diserbo)
multcomp::cld(medie, adjust="none", Letters=LETTERS)
## Diserbo = parz:
## Lavorazione emmean SE df lower.CL upper.CL .group
## MIN 6.00 0.684 15 4.54 7.45 A
## SUP 8.48 0.684 15 7.02 9.93 B
## PROF 10.63 0.684 15 9.17 12.09 C
##
## Diserbo = tot:
## Lavorazione emmean SE df lower.CL upper.CL .group
## MIN 8.98 0.684 15 7.53 10.44 A
## SUP 9.14 0.684 15 7.68 10.60 A
## PROF 9.21 0.684 15 7.75 10.66 A
##
## Results are averaged over the levels of: Blocco
## Confidence level used: 0.95
## significance level used: alpha = 0.05
medie <- emmeans(mod, ~Lavorazione:Diserbo)
multcomp::cld(medie, adjust="none", Letters=LETTERS)
## Lavorazione Diserbo emmean SE df lower.CL upper.CL .group
## MIN parz 6.00 0.684 15 4.54 7.45 A
## SUP parz 8.48 0.684 15 7.02 9.93 B
## MIN tot 8.98 0.684 15 7.53 10.44 BC
## SUP tot 9.14 0.684 15 7.68 10.60 BC
## PROF tot 9.21 0.684 15 7.75 10.66 BC
## PROF parz 10.63 0.684 15 9.17 12.09 C
##
## Results are averaged over the levels of: Blocco
## Confidence level used: 0.95
## significance level used: alpha = 0.05In questo caso non c’è nessuna differenza, dato che non abbiamo implementato nessuna correzione per la molteplicità. Altrimenti, le tre situazioni sarebbero diverse, in quanto nel primo caso avremmo fatto solo tre confronti, nel secondo caso ne avremmo fatti sei, nel terzo caso 15, con un diverso livello di correzione per la molteplicità.
11.11 Per approfondire un po’….
11.11.1 Anova a due vie: scomposizione ‘manuale’ della varianza
Anche nel caso dell’ANOVA a due vie, illustriamo i calcoli necessari per la scomposizione ‘manuale’ della varianza. Il punto di partenza, come al solito, sono le medie per i livelli di ogni fattore sperimentale e per le loro combinazioni, che sono date più sotto, in forma di matrici (ma nessuna paura, è solo per comodità!).
Le medie delle combinazioni ‘lavorazioni \(\times\) diserbo’ sono:
\[ \bar{Y}_{ij.} = \left[ {\begin{array}{rr} 5.99500 & 8.98275 \\ 10.62875 & 9.20675 \\ 8.47525 & 9.14125 \\ \end{array}} \right]\]
Per le lavorazioni e per i diserbi abbiamo:
\[ \bar{Y}_{i..} = \left[ {\begin{array}{r} 7.488875 \\ 9.917750 \\ 8.808250 \end{array}} \right]\]
\[ \bar{Y}_{.j.} = \left[ {\begin{array}{r} 7.488875 \\ 9.917750 \\ 8.808250 \end{array}} \right]\]
Le medie dei blocchi, sono, invece:
\[ \bar{Y}_{..k} = \left[ {\begin{array}{r} 9.385500 \\ 8.347500 \\ 8.557833 \\ 8.662333 \end{array}} \right]\]
La media generale è \(\bar{Y}_{...} = 8.738292\).
Per calcolare le devianze degli effetti principali (blocchi, lavorazioni e diserbi), come primo passaggio, calcoliamo gli scostamenti tra le medie e la media generale e, quindi, sottraiamo da ogni media la media generale. Ricordiamo che questi scarti non sono altro che gli effetti dei trattamenti e, nel caso in cui si sia adottata un vincolo sulla somma, questi coincidono con i parametri di un modello lineare. Per cui:
\[\bar{Y}_{i..} - \bar{Y}_{...} = \alpha_i = \left[ {\begin{array}{r} -1.24941667 \\ 1.17945833 \\ 0.06995833 \end{array}} \right]\]
\[ \bar{Y}_{.j.} - \bar{Y}_{...} = \beta_j = \left[ {\begin{array}{r} -0.3719583 \\ 0.3719583 \end{array}} \right]\]
\[ \bar{Y}_{..k} - \bar{Y}_{...} = \gamma_k = \left[ {\begin{array}{r} 0.6472083\\ -0.3907917\\ -0.1804583\\ -0.07595833 \end{array}} \right]\]
Per quanto riguarda la devianza di blocchi, lavorazioni e diserbo, basta calcolare il quadrato degli scarti e sommare i valori ottenuti, moltiplicando per il numero di osservazioni che abbiamo per ogni blocco/lavorazione/diserbo. In questo modo, considerando che, in un blocco, abbiamo 6 osservazioni, la devianza dei blocchi è:
\[SS_b = 6 \times \left( 0.6472083^2 + 0.3907917^2 + 0.1804583^2 + 0.07595833 ^ 2 \right) = 3.65959\]
La devianza delle lavorazioni, considerando che, per ognuna, abbiamo 8 valori, è:
\[ SS_l = 8 \times \left(1.24941667^2 + 1.17945833^2 + 0.06995833^2 \right) = 23.65647 \]
Per il diserbo:
\[ SS_l = 12 \times \left(0.3719583^2 + 0.3719583 ^ 2 \right) = 3.320472 \]
Per l’interazione, non possiamo procedere nello stesso modo, in quanto la variabilità esistente tra le medie delle sei combinazioni è il risultato, non solo dell’eventuale interazione, ma anche degli effetti principali. Infatti, se ricordiamo il modello lineare per un disegno a due vie, risulta che il valore atteso per una combinazione è:
\[ \bar{Y}_{ij.} = \mu + \alpha_i + \beta_j + \alpha\beta_{ij}\]
Se abbiamo utilizzato il vincolo sulla somma, \(\mu\) è la media generale, \(\alpha_i\) sono gli effetti delle lavorazioni (l’ultima colonna della tabella sovrastante), \(\beta_j\) sono gli effetti dei diserbi (ultima riga della tabella sovrastante). Di conseguenza, gli effetti dell’interazione sono:
\[ \alpha\beta_{ij} = \bar{Y}_{ij.} - \bar{Y}_{...} - \alpha_i - \beta_j \]
Ora, siccome
\[\alpha_i = \bar{Y}_{i..} - \bar{Y}_{...}\] e
\[\beta_j = \bar{Y}_{.j.} - \bar{Y}_{...}\]
possiamo scrivere:
\[ \alpha\beta_{ij} = \bar{Y}_{ij.} - \bar{Y}_{...} - \bar{Y}_{i..} + \bar{Y}_{...} - \bar{Y}_{.j.} + \bar{Y}_{...} = \bar{Y}_{ij.} - \bar{Y}_{i..} - \bar{Y}_{.j.} + \bar{Y}_{...}\]
Ad esempio:
\[ \alpha\beta_{11} = 5.995 - 7.488875 - 8.366333 + 8.738292 = - 1.121916\]
Completando i calcoli:
\[ \alpha\beta_{ij} = \left[ {\begin{array}{rr} -1.1219 & 1.1219 \\ 1.0830 & -1.0830 \\ 0.0390 & -0.0390\\ \end{array}} \right]\]
Elevando al quadrato, sommando e moltiplicando per quattro otteniamo la devianza dell’interazione, pari a:
\[ SS_{ld} = 4 \times \left(1.1219^2+ 1.1219^2 +1.0830^2 +1.0830^2 + 0.0390^2 +0.0390^2 \right)= 19.46456\]
Questi calcoli manuali possono essere utili per meglio comprendere il senso della scomposizione della varianza, ma sono da considerare obsoleti, in quanto, nell’uso comune, nessuno li esegue più senza l’aiuto di un computer.