This is a follow-up post. If you are interested in other posts of this series, please go to: https://www.statforbiology.com/tags/drcte/. All these posts exapand on a paper that we have recently published in the Journal ‘Weed Science’; please follow this link to the paper.
Comparing germination/emergence for several seed lots
Very often, seed scientists need to compare the germination behavior of different seed populations, e.g., different plant species, or one single plant species submitted to different temperatures, light conditions, priming treatments and so on. How should such a comparison be performed? For example, if we have submitted several seed samples to different environmental conditions, how do we decide whether the germinative response is affected by those environmental conditions?
If the case that we have replicates for all experimental treatments, e.g. several Petri dishes, one possible line of attack is to take a summary measure for each dish and use that for further analyses, in a two-steps fashion. For example, we could take the total number of germinated seeds (Pmax) in each dish and use the resulting values to parameterise some sort of ANOVA-like model and test the significance of all effects.
This method of data analysis is known as ‘response feature analysis’ and it may be regarded as ‘very traditional’, in the sense that it is often found in literature; although it is not wrong, it is, undoubtedly, sub-optimal. Indeed, two seed lots submitted to different treatments may show the same total number of germinated seeds, but a different velocity or uniformity of germination. In other words, if we only consider, e.g., the Pmax, we can answer the question: “do the seed lots differ for their germination capability?”, but not the more general question: “are the seed lots different?”.
In order to answer this latter question, we should consider the entire time-course of germination and not only one single summary statistic. In other words, we need a method to fit and compare several time-to-event curves.
A motivating example
Let’s take a practical approach and start from an example: a few years ago, some colleagues of mine studied the germination behavior of a plant species (Verbascum arcturus), in different conditions. In detail, they considered the factorial combination of two storage periods (LONG and SHORT storage) and two temperature regimes (FIX: constant daily temperature of 20°C; ALT: alternating daily temperature regime, with 25°C during daytime and 15°C during night time, with a 12:12h photoperiod). If you are a seed scientist and are interested in this experiment, you’ll find detail in Catara et al. (2016).
If you are not a seed scientist, you may wonder why my colleagues made such an assay; well, there is evidence that, for some plant species, the germination ability improves over time, after seed maturation. Therefore, if we take seeds and store them for different periods of time, there might be an effect on their germination traits. Likewise, there is also evidence that germinations may be hindered if seed is not submitted to daily temperature fluctuations. For seed scientists, all these mechanisms are very important, as they permit to trigger the germinations when the environmental conditions are favorable for seedling survival.
Let’s go back to our assay: the experimental design consisted of four experimental ‘combinations’ (LONG-FIX, LONG-ALT, SHORT-FIX and SHORT-ALT) and four replicates for each combination. One replicate consisted of a Petri dish, that is a small plastic box containing humid blotting paper, with 25 seeds of V. arcturus. In all, there were 16 Petri dishes, which were put in climatic chambers with the appropriate conditions. During the assay, my colleagues made daily inspections: germinated seeds were counted and removed from the dishes. Inspections were made for 15 days, until no more germinations could be observed.
The original dataset is available on a web repository: let’s load and have a look at it.
datasetOr <- read.csv("https://www.casaonofri.it/_datasets/TempStorage.csv",
header = T, check.names = F)
head(datasetOr)
## Dish Storage Temp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
## 1 1 Low Fix 0 0 0 0 0 0 0 0 3 4 6 0 1 0 3
## 2 2 Low Fix 0 0 0 0 1 0 0 0 2 7 2 3 0 5 1
## 3 3 Low Fix 0 0 0 0 1 0 0 1 3 5 2 4 0 1 3
## 4 4 Low Fix 0 0 0 0 1 0 3 0 0 3 1 1 0 4 4
## 5 5 High Fix 0 0 0 0 0 0 0 0 1 2 5 4 2 3 0
## 6 6 High Fix 0 0 0 0 0 0 0 0 2 2 7 8 1 2 1We have one row per Petri dish; the first three columns show, respectively, the dish number, storage and temperature conditions. The next 15 columns represent the inspection times (from 1 to 15) and contain the counts of germinated seeds. The research question is:
Is germination behavior affected by storage and temperature conditions?
Reshaping the data
The original dataset for our example is in a WIDE format and, as we have shown in a previous post (go to this link), it is necessary to reshape it in LONG GROUPED format, by using the melt_te() function in the ‘drcte’ package. As I said in my previous posts, this package can be installed from gitHub (see the code at: this link).
The melt_te() function needs to receive the columns storing the counts (‘count_cols = 4:18’), the columns storing the factor variables (‘treat_cols = c(“Dish”, “Storage”, “Temp”)’), a vector of monitoring times (‘monitimes = 1:15’) and a vector with the total number of seeds in each Petri dish (‘n.subjects = rep(25,16)’).
library(drcte)
dataset <- melt_te(datasetOr, count_cols = 4:18,
treat_cols = c("Dish", "Storage", "Temp"),
monitimes = 1:15, n.subjects = rep(25, 16))
head(dataset, 16)
## Dish Storage Temp Units timeBef timeAf count nCum propCum
## 1 1 Low Fix 1 0 1 0 0 0.00
## 2 1 Low Fix 1 1 2 0 0 0.00
## 3 1 Low Fix 1 2 3 0 0 0.00
## 4 1 Low Fix 1 3 4 0 0 0.00
## 5 1 Low Fix 1 4 5 0 0 0.00
## 6 1 Low Fix 1 5 6 0 0 0.00
## 7 1 Low Fix 1 6 7 0 0 0.00
## 8 1 Low Fix 1 7 8 0 0 0.00
## 9 1 Low Fix 1 8 9 3 3 0.12
## 10 1 Low Fix 1 9 10 4 7 0.28
## 11 1 Low Fix 1 10 11 6 13 0.52
## 12 1 Low Fix 1 11 12 0 13 0.52
## 13 1 Low Fix 1 12 13 1 14 0.56
## 14 1 Low Fix 1 13 14 0 14 0.56
## 15 1 Low Fix 1 14 15 3 17 0.68
## 16 1 Low Fix 1 15 Inf 8 NA NAIn the resulting data frame, the column ‘timeAf’ contains the time when the inspection was made and the column ‘count’ contains the number of germinated seeds (e.g. 9 seeds were counted at day 9). These seeds did not germinate exactly at day 9; they germinated within the interval between two inspections, that is between day 8 and day 9. The beginning of the interval is given as the variable ‘timeBef’. Apart from these three columns, we have the columns for the blocking factor (‘Dish’ and ‘Units’; this latter column is added by the R function, but it is not useful in this case) and for the treatment factors (‘Storage’ and ‘Temp’) plus two other additional columns (‘nCum’ and ‘propCum’), which we are not going to use for our analyses.
Fitting several time-to-event curves
In this case, we have reasons to believe that the germination time-course can be described by using a parametric log-logistic time-to-event model, which can be estimated by using either the drm() function in the ‘drc’ package (Ritz et al., 2019) or the drmte() function in the ‘drcte’ package (Onofri et al., submitted). In both cases, we have to include the experimental factor (‘curveid’ argument), to specify that we want to fit a different curve for each combination of storage and temperature.
library(tidyverse)
dataset <- dataset %>%
mutate(across(1:3, .fns = factor))
mod1 <- drmte(count ~ timeBef + timeAf, fct = loglogistic(),
data = dataset,
curveid = Temp:Storage)
summary(mod1)
##
## Model fitted: Log-logistic distribution of event times
##
## Robust estimation: no
##
## Parameter estimates:
##
## Estimate Std. Error t-value p-value
## b:Fix:Low 4.974317 0.819632 6.0690 1.287e-09 ***
## b:Fix:High 11.476618 1.254439 9.1488 < 2.2e-16 ***
## b:Alt:Low 7.854558 5.239783 1.4990 0.1339
## b:Alt:High 10.600439 1.014061 10.4534 < 2.2e-16 ***
## d:Fix:Low 0.998474 0.150189 6.6481 2.968e-11 ***
## d:Fix:High 0.861711 0.038987 22.1027 < 2.2e-16 ***
## d:Alt:Low 1.405930 5.607529 0.2507 0.8020
## d:Alt:High 0.948113 0.024298 39.0208 < 2.2e-16 ***
## e:Fix:Low 12.009974 0.987039 12.1677 < 2.2e-16 ***
## e:Fix:High 10.906963 0.190532 57.2447 < 2.2e-16 ***
## e:Alt:Low 17.014976 13.214403 1.2876 0.1979
## e:Alt:High 9.585255 0.166937 57.4183 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1In a previous post I have described a log-logistic time-to-event model (see here), which has a sygmoidal shape, with the three parameters \(b\), \(d\) and \(e\). These parameters represent, respectively, the slope at inflection point, the higher asymptote (i.e. the maximum proportion of germinated seeds) and the median germination time. As we have four curves, we have a number of 12 estimated parameters.
We see that the optimization routines returns an unreasonable value for the higher asymptote for one of the curves (\(d\) = 1.40 with Alt:Low); it is unreasonable because the maximum proportion of germinated seeds may not exceed 1. Therefore, we should refit the model by adding a constraint (\(d \le 1\)) for all the four curves. We can do so by setting the ‘upperl’ argument to 1 for the 5th through 8th estimands.
mod1 <- drmte(count ~ timeBef + timeAf, fct = loglogistic(),
data = dataset,
curveid = Temp:Storage,
upperl = c(NA, NA, NA, NA, 1, 1, 1, 1, NA, NA, NA, NA))
summary(mod1)
##
## Model fitted: Log-logistic distribution of event times
##
## Robust estimation: no
##
## Parameter estimates:
##
## Estimate Std. Error t-value p-value
## b:Fix:Low 4.979667 0.818408 6.0846 1.168e-09 ***
## b:Fix:High 11.471633 1.254025 9.1478 < 2.2e-16 ***
## b:Alt:Low 8.408185 2.232684 3.7660 0.0001659 ***
## b:Alt:High 10.605820 1.014524 10.4540 < 2.2e-16 ***
## d:Fix:Low 0.997283 0.149233 6.6827 2.345e-11 ***
## d:Fix:High 0.861709 0.038999 22.0955 < 2.2e-16 ***
## d:Alt:Low 1.000000 0.881619 1.1343 0.2566785
## d:Alt:High 0.948132 0.024282 39.0467 < 2.2e-16 ***
## e:Fix:Low 12.004515 0.981265 12.2337 < 2.2e-16 ***
## e:Fix:High 10.907108 0.190612 57.2214 < 2.2e-16 ***
## e:Alt:Low 15.903084 2.872251 5.5368 3.080e-08 ***
## e:Alt:High 9.585293 0.166873 57.4407 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
r
plot(mod1, log = "", legendPos = c(6, 1), xlab = "Time",
ylab = "Cumulative probability of germination")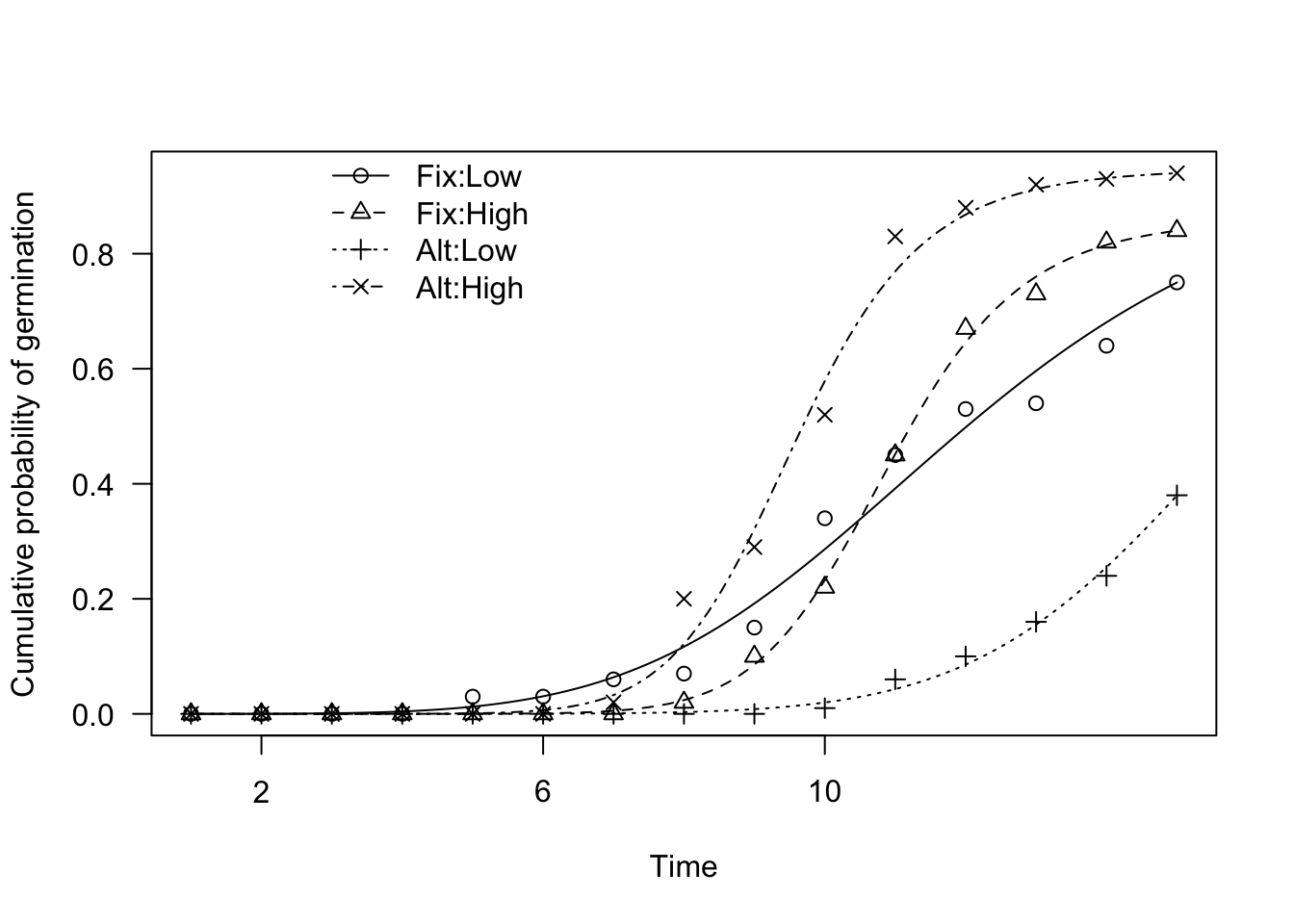
From the graph we see that there are visible differences between the fitted curves (the legend considers the curves in alphabetical order, i.e. 1: Fix-Low, 2: Fix-High, 3: Alt-Low and 4: Alt-High). Now, the question is: could we say that those differences are only due to chance (null hypothesis)?
In order to make such a test, we could compare the logarithm of the likelihood for the fitted model with the logarithm of the likelihood for a ‘reduced’ model, where all curves have been pooled into one common curve for all treatment levels. The higher the log-likelihood difference, the lowest the probability that the null is true (Likelihood Ratio Test; LRT).
A LRT for parametric models can be done with the compCDF() function in the ‘drcte’ package, as shown in the box below.
compCDF(mod1)
##
##
## Likelihood ratio test
## NULL: time-to-event curves are equal
##
## Observed LR value: 202.8052
## Degrees of freedom: 9
## P-value: 8.551556e-39We see that the LR value, that relates to the difference between the two log-likelihoods, is rather high and equal to 202; when the null is true, this LR value has an approximate Chi-square distribution; accordingly, we see that the P-level is very low and, thus, the null should be rejected.
It general, the results of LRTs should be taken with care, particularly when the observed data are not independent from one another. Unfortunately, the lack of independence is an intrinsic characteristic of germination/emergence assays, where seeds are, most often, clustered within Petri dishes or other types of containers.
In this example, we got a very low p-level, which leaves us rather confident that the difference between time-to-event curves is significant. More generally, instead of relying on a chi-square approximation, we should better use a grouped-permutation approach. This technique is based on the idea that, when the difference between curves is not significant, we should be able to freely permute the labels (treatment level) among Petri dishes (clustering units) and, consequently, build an empirical distribution for the LR statistic under the null (permutation distribution). The p-level is related to the proportion of LR values in the permutation distribution that are higher than the observed value (i.e.: 202.8)
In the code below, we show how we can do this. The code is rather slow and, therefore, we should not use a very high number of permutation; the default is 199, that gives us a minimum p-value of 0.005. We see that we can confirm that the difference between curves is highly significant.
compCDF(mod1, type = "permutation", units = dataset$Dishes)
## Likelihood ratio test (permutation based)
## NULL: time-to-event curves are equal
##
## Observed LR value: 202.8052
## Degrees of freedom: 9
## Naive P-value: 8.551556e-39
## Permutation P-value (B = 199): 0.005Comparing non-parametric curves
In the above example, we have decided to fit a parametric time-to-event model. However, in other situations, we might be interested in fitting a non-parametric time-to-event model (NPMLE; see here) and compare the curves for different treatment levels. In practice, nothing changes with respect to the approach I have shown above: first of all, we fit the NPMLEs with the following code:
modNP <- drmte(count ~ timeBef + timeAf, fct = NPMLE(),
data = dataset,
curveid = Temp:Storage)
plot(modNP, log = "", legendPos = c(6, 1))
Next, we compare the non-parametric curves, in the very same fashion as above:
compCDF(modNP, units = dataset$Units)
## Exact Wilcoxon test (permutation form)
## NULL: time-to-event curves are equal
##
## level n Scores
## 1 Fix:Low 100 2.5350
## 2 Fix:High 100 6.4600
## 3 Alt:Low 100 -51.2275
## 4 Alt:High 100 42.2325
##
## Observed T value: 44.56
## Permutation P-value (B = 199): 0.005Obviously, with NPMLEs, a different test statistic is used in the background; the default one is the Wilcoxon rank sum score, although two types of log-rank scores are also implemented (Sun’s scores and Finkelstein’s scores; see Fay and Shaw 2010). Permutation based P-values are calculated and reported.
The approach is exactly the same with Kernel Density Estimators (KDE; see here). First we fit the four curves curves, by including the experimental factor as the ‘curveid’ argument:
modKD <- drmte(count ~ timeBef + timeAf, fct = KDE(),
data = dataset,
curveid = Temp:Storage)
plot(modKD, log = "", legendPos = c(6, 1))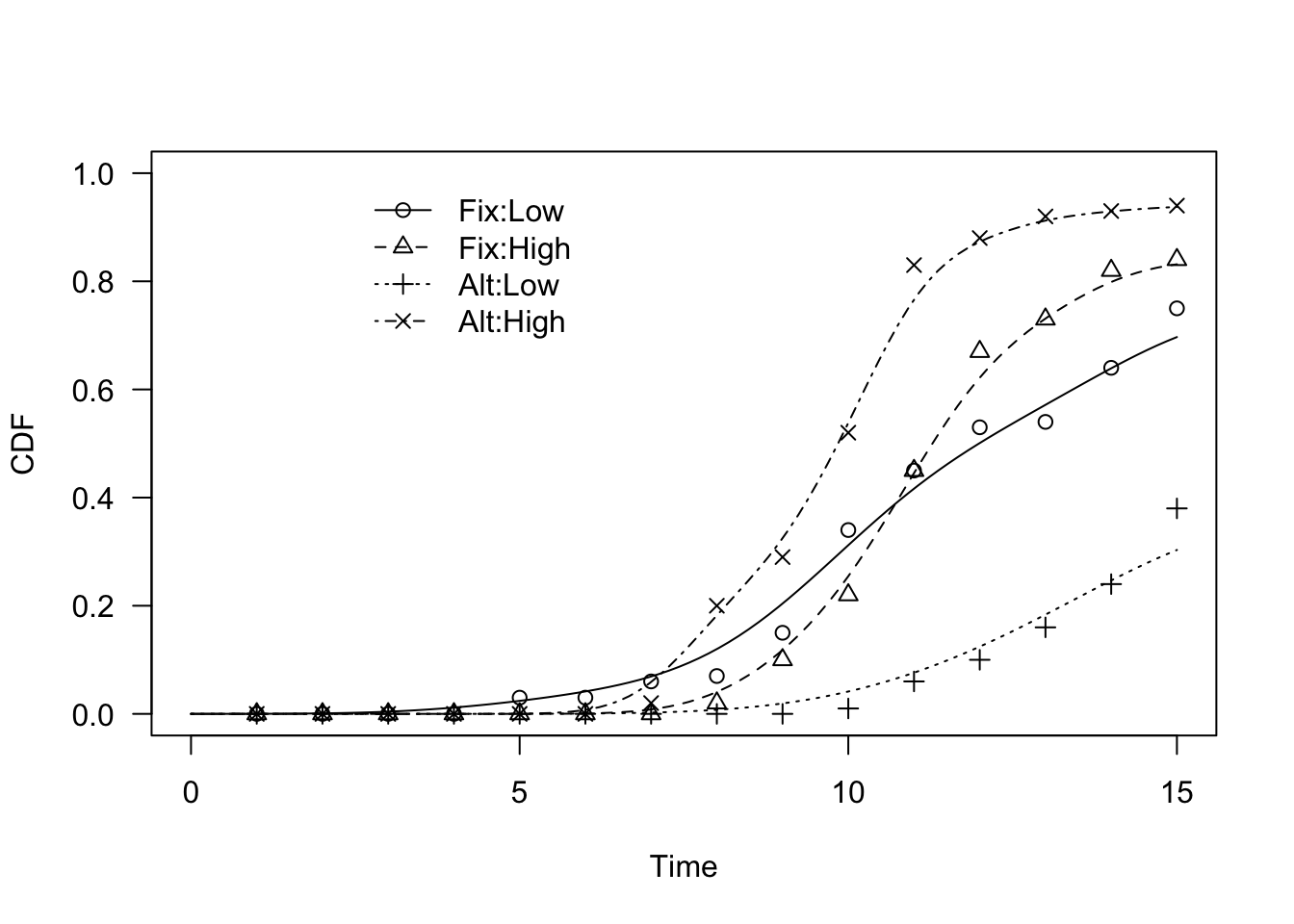
Second, we compare those curves, by using the compCDF() function:
compCDF(modKD, units = dataset$Units)
## Permutation test based on a Cramer-von-Mises type distance (Barreiro-Ures et al., 2019)
## NULL HYPOTHESIS: time-to-event curves are equal
##
## level n D
## 1 Fix:Low 100 0.0579661
## 2 Fix:High 100 0.1347005
## 3 Alt:Low 100 4.1378209
## 4 Alt:High 100 3.8581487
##
## Observed D value = 2.0472
## P value = 0.005In this case, a Cramér‐von Mises type distance among curves is used (Barreiro-Ures et al., 2019), which, roughly speaking, is based on the integrated distance between the KDEs for the different groups and the pooled KDE for all groups. Permutation based P-values are also calculated and reported.
We do hope that this post helps you test your hypotheses about seed germination/emergence in a reliable way.
Thanks for reading and, please, accept my best:

Prof. Andrea Onofri
Department of Agricultural, Food and Environmental Sciences
University of Perugia (Italy)
Send comments to: andrea.onofri@unipg.it
References
- Barreiro‐Ures, D, M Francisco‐Fernández, R Cao, BB Fraguela, R Doallo, JL González‐Andújar, M Reyes (2019) Analysis of interval‐grouped data in weed science: The binnednp Rcpp package. Ecol Evol 9:10903–10915
- Catara, S., Cristaudo, A., Gualtieri, A., Galesi, R., Impelluso, C., Onofri, A., 2016. Threshold temperatures for seed germination in nine species of Verbascum (Scrophulariaceae). Seed Science Research 26, 30–46.
- Fay, MP, PA Shaw (2010) Exact and Asymptotic Weighted Logrank Tests for Interval Censored Data: The interval R Package. Journal of Statistical Software 36:1–34
- Ritz, C., Jensen, S. M., Gerhard, D., Streibig, J. C. (2019) Dose-Response Analysis Using R CRC Press