THE CODE IN THIS POST WAS UPDATED ON JANUARY 2022
I am locked at home, due to the COVID-19 emergency in Italy. Luckily I am healthy, but there is not much to do, inside. I thought it might be nice to spend some time to talk about seed germination models and the connections with survival analysis.
We all know that seeds need water to germinate. Indeed, the absorption of water activates the hydrolytic enzymes, which break down food resources stored in seeds and provide energy for germination. As the consequence, there is a very close relationship between water content in the substrate and germination velocity: the higher the water content the quickest the germination, as long as the availability of oxygen does not become a problem (well, water and oxygen in soil may compete for space and a high water content may result in oxygen shortage).
Indeed, it is relevant to build germination models, linking the proportion of germinated seeds to water availability in the substrate; these models are usually known as hydro-time (HT) models. The starting point is the famous equation of Bradford (1992), where the germination rate (GR) for the \(i-th\) seed in the lot is expressed as a linear function of water potential in the substrate (\(\Psi\)):
\[ GR_i = \textrm{max} \left( \frac{\Psi - \Psi_{b(i)}}{\theta_H}; 0 \right) \quad \quad \quad \quad (1)\]
In that equation, \(\Psi_{b(i)}\) is the base water potential for the \(i-th\) seed and \(\theta_H\) is the hydro-time constant, expressed as MPa day or MPa hour. The concept is relatively simple: we just need to remember that the water can only move from a position with a higher water potential to a position with a lower water potential. Therefore, a seed cannot germinate when its base water potential is higher than the water potential in the substrate.
When \(\Psi > \Psi_b(i)\), the germination rate of the \(i-th\) seed is linearly related to \(\Psi\): the higher this latter value, the higher the germination rate. Now we should consider that the germination rate is the inverse of the germination time (\(GR = 1/t\)); thus, the higher the GR, the shortest the germination time. Germination is achieved at the time \(t\) when:
\[ t \, \left( \Psi - \Psi_{b(i)} \right) = \theta_H \quad \quad \quad (2)\]
Elsewhere in this website, I show that Equation 1 can be fitted to germination data in a two-steps fashion. In this page we will see how we can embed Equation 1 into a time-to-event model, to predict the proportion of germinated seeds, depending on time and water content in the substrate. As usual, let’s start from a practical example.
The dataset
The germination of rapeseed (Brassica napus L. var. oleifera, cv. Excalibur) was tested at fourteen different water potentials (0, -0.03, -0.15, -0.3, -0.4, -0.5, -0.6, -0.7, -0.8, -0.9, -1, -1.1, -1.2, -1.5 MPa), which were created by using a polyethylene glycol solution (PEG 6000). For each water potential level, three replicated Petri dishes with 50 seeds were incubated at 20°C. Germinated seeds were counted and removed every 2-3 days for 14 days.
The dataset was published by Pace et al. (2012) and it is available as rape in the drcSeedGerm package, which needs to be installed from github (see below). Furthermore, the package drcte is necessary to fit time-to-event models and it should also be installed from gitHub. Please, make sure you have the most updated version for both packages.
The following code loads the necessary packages, loads the dataset rape and shows the first six lines.
# library(devtools)
# install_github("OnofriAndreaPG/drcSeedGerm")
# install_github("OnofriAndreaPG/drcte")
library(drcSeedGerm)
library(drcte)
data(rape)
head(rape)
## Psi Dish timeBef timeAf nSeeds nCum propCum
## 1 0 1 0 3 49 49 0.98
## 2 0 1 3 4 0 49 0.98
## 3 0 1 4 5 0 49 0.98
## 4 0 1 5 7 0 49 0.98
## 5 0 1 7 10 0 49 0.98
## 6 0 1 10 14 0 49 0.98We can see that the data are grouped by assessment interval: ‘timeAf’ represents the moment when germinated seeds were counted, while ’timeBef’ represents the previous inspection time (or the beginning of the assay). The column ’nSeeds’ is the number of seeds that germinated during the time interval between ‘timeBef’ and ‘timeAf. The ’propCum’ column contains the cumulative proportions of germinated seeds and it is not necessary for time-to-event models.
Building hydro-time models
Models based on the distribution of germination time
How can we rework Equation 1 to predict the proportion of germinated seeds, as a function of time and water potential? One line of attack follows the proposal we made in a relatively recent paper (Onofri at al., 2018). We start from the idea that the time course of the proportion of germinated seeds (\(P\)) is expected to increase over time, according to a S-shaped curve, such as the usual log-logistic cumulative probability function (other cumulative distribution functions can be used; see our original paper):
\[P(t) = \frac{ d }{1 + \exp \left\{ b \left[ \log(t) - \log( e ) \right] \right\} } \quad \quad \quad (3)\]
where \(e\) is the median germination time, \(b\) is the slope at the inflection point and \(d\) is the maximum germinated proportion. Considering that the germination rate is the inverse of germination time, we can write:
\[P(t) = \frac{ d }{1 + \exp \left\{ b \left[ \log(t) - \log(1 / GR_{50} ) \right] \right\} } \quad \quad \quad (4)\]
where \(GR_{50}\) is the median germination rate in the population. We can now express \(GR_{50}\), \(b\) and \(d\) as linear/nonlinear functions of \(\Psi\) (temperature and other environmental variables can be included as well. See our original paper):
\[P(t, \Psi) = \frac{ h_1(\Psi) }{1 + \exp \left\{ b \left[ \log(t) - \log(1 / \left[ GR_{50}(\Psi) \right] ) \right] \right\} } \quad \quad \quad (5)\]
In our paper, for \(GR_{50}\), we slightly reparameterised Equation 1 above:
\[ GR_{50}(\Psi) = \textrm{max} \left( \frac{\Psi - \Psi_{b(50)}}{\theta_H}; 0 \right) \quad \quad \quad \quad (6)\]
where \(\Psi_{b(50)}\) is the median base water potential in the population.
For \(d\), we used a shifted exponential distribution, which implies that germination capability is fully determined by the distribution of base water potential within the population and no germination occurs at \(\Psi \leq \Psi_b\):
\[d = h_1(\Psi ) = \textrm{max} \left\{ G \, \left[ 1 - \exp \left( \frac{ \Psi - \Psi_{b(50)} }{\sigma_{\Psi_b}} \right) \right]; 0 \right\} \quad \quad \quad (7)\]
In the above equation, \(\sigma_{\Psi_b}\) represents the variability of \(\Psi_b\) within the population, which determines the steepness of the increase in \(d\) as \(\Psi\) increases. \(G\) is the germinable fraction, accounting for the fact that \(d\) may not reach 1, regardless of time and water potential.
The parameter \(b\) was assumed to be constant and independent on \(\Psi\). In the end, our hydro-time model is composed by four sub-models:
- a cumulative probability function (log-logistic, in our example), based on the three parameters \(d\), \(b\) and \(e = 1/GR_{50}\);
- a sub-model expressing \(d\) as a function of \(\Psi\);
- a sub-model expressing \(GR_{50}\) as a function of \(\Psi\);
- a sub-model expressing \(b\) as a function of \(\Psi\), although, this was indeed a simple identity model \(b(\Psi) = b\).
This hydro-time model was implemented in R as the HTE1() function, and it is available within the drcSeedGerm package, together with the appropriate self-starting routine. It can be fitting by using the drmte() function in the drcte package.
modHTE <- drmte(nSeeds ~ timeBef + timeAf + Psi,
data = rape, fct = HTE1())
summary(modHTE)
##
## Model fitted: Hydro-time model with shifted exponential for Pmax and linear model for GR50
##
## Robust estimation: no
##
## Parameter estimates:
##
## Estimate Std. Error t-value p-value
## G:(Intercept) 0.9577918 0.0063667 150.438 < 2.2e-16 ***
## Psib:(Intercept) -1.0397239 0.0047017 -221.138 < 2.2e-16 ***
## sigmaPsib:(Intercept) 0.1108891 0.0087598 12.659 < 2.2e-16 ***
## thetaH:(Intercept) 0.9061385 0.0301594 30.045 < 2.2e-16 ***
## b:(Intercept) 4.0273963 0.1960845 20.539 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1As seeds are clustered in Petri dishes, in order not to violate the independence assumption, it is preferable to get cluster robust standard errors. One possibility is to use the grouped version of the sandwich estimator, as available in the ‘sandwich’ package (Berger, 2017). The function coeftest() is available in the ‘lmtest’ package (Zeileis, 2002) and its usage is shown in the box below.
lmtest::coeftest(modHTE, vcov = vcovCL, cluster = rape$Dish)
##
## t test of coefficients:
##
## Estimate Std. Error t value Pr(>|t|)
## G:(Intercept) 0.9577918 0.0080923 118.3591 < 2.2e-16 ***
## Psib:(Intercept) -1.0397239 0.0047063 -220.9206 < 2.2e-16 ***
## sigmaPsib:(Intercept) 0.1108891 0.0121879 9.0983 < 2.2e-16 ***
## thetaH:(Intercept) 0.9061385 0.0410425 22.0781 < 2.2e-16 ***
## b:(Intercept) 4.0273963 0.1934513 20.8187 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Once the model is fitted, we may be interested in using the resulting curve to retrieve some biologically relevant information. For example, it may be interesting to retrieve the germination rates for some selected percentiles (e.g., the 30th, 20th and 10th percentiles). This is possible using the GRate() function, that is a wrapper for the original ED() function in the package drc. It reverses the behavior of the ED() function, in the sense that it considers, by default, the percentiles for the whole population, including the ungerminated fraction, which is, in our opinion, the most widespread interpretation of germination rates in seed science. The GRate() function works very much like the ED() function, although additional variables, such as the selected \(\Psi\) level can be specified by using the argument x2.
#Naive standard errors
GRate(modHTE, x2 = -1, respLev = c(30, 20, 10))
## Estimate SE
## GR:1:30 0.00000000 0.000000000
## GR:1:20 0.03579236 0.005808732
## GR:1:10 0.05130356 0.006221881In this example, we see that the \(GR_{30}\) cannot be calculated, as the germination capacity did not reach 30% at the selected water potential level (\(-1 \,\, MPa\)).
As we said, cluster robust standard errors are recommended. The GRate() function allows entering a user-defined variance-covariance matrix, that is obtained by using the vcovCL() function in the sandwich package. If necessary, germination times can be obtained in a similar way, by using the GTime() function.
#Cluster robust standard errors
sc <- vcovCL(modHTE, cluster = rape$Dish)
GRate(modHTE, x2 = -1, respLev = c(30, 20, 10), vcov.=sc)
## Estimate SE
## GR:1:30 0.00000000 0.000000000
## GR:1:20 0.03579236 0.005450975
## GR:1:10 0.05130356 0.005869140
#Germination times
GTime(modHTE, x2 = -1, respLev = c(30, 20, 10), vcov.=sc)
## Estimate SE
## T:1:30 Inf NA
## T:1:20 27.93892 4.25494
## T:1:10 19.49183 2.22987Last, but not least, we can predict the proportion of germinated seeds at given time and water potential level.
predictSG(modHTE, se.fit=T, vcov. = vcovCL,
newdata = data.frame(Time=c(10, 10, 10),
Psi=c(-1.5, -0.75, 0))
)
## Prediction SE
## [1,] 0.0000000 0.00000000
## [2,] 0.8794025 0.03907487
## [3,] 0.9576590 0.01493134Models based on the distribution of \(\Psi_b\)
Another type of hydro-time model was proposed by Bradford (2002) and later extended by Mesgaran et al (2013). This approach starts always from Equation 1; from that equation, considering that the germination time is the inverse of the GR, we can easily get to the following equation:
\[\Psi_b = \Psi - \frac{\theta_H}{t} \quad \quad \quad (8)\]
where \(t\) is the germination time. What does this equation tell us? Let’s assume that the hydro-time to germination is 10 \(MPa \, d\) and the environmental water potential is -1 \(MPa\). A single seed germinates in exactly one day, if its base water potential is \(-1 - 10/1 = -11\). If the base water potential is higher, germination will take more than one day; if it is lower, germination will take less than one day. But now, the following questions come: how many seeds in a population will be able to germinate in one day? And in two days? And in \(t\) days?
We know that the seeds within a population do not germinate altogether in the same moment, as they have different individual values of base water potential. If the population is big enough, we can describe the variation of \(\Psi_b\) within the population by using some density function, possibly parameterised by way of a location (\(\mu\)) and a scale (\(\sigma\)) parameter:
\[ \Psi_b \sim \phi \left( \frac{\Psi_b - \mu}{\sigma} \right) \quad \quad \quad (9)\]
This is easier to understand if we make a specific example. Let’s assume that the distribution of \(\Psi_b\) values within the population is gaussian, with mean \(\mu = -9\) and standard deviation \(\sigma = 1\). Let’s also assume that the hydro-time parameter (\(\theta_H\)) is constant within the population. We have the situation depicted in the figure below.
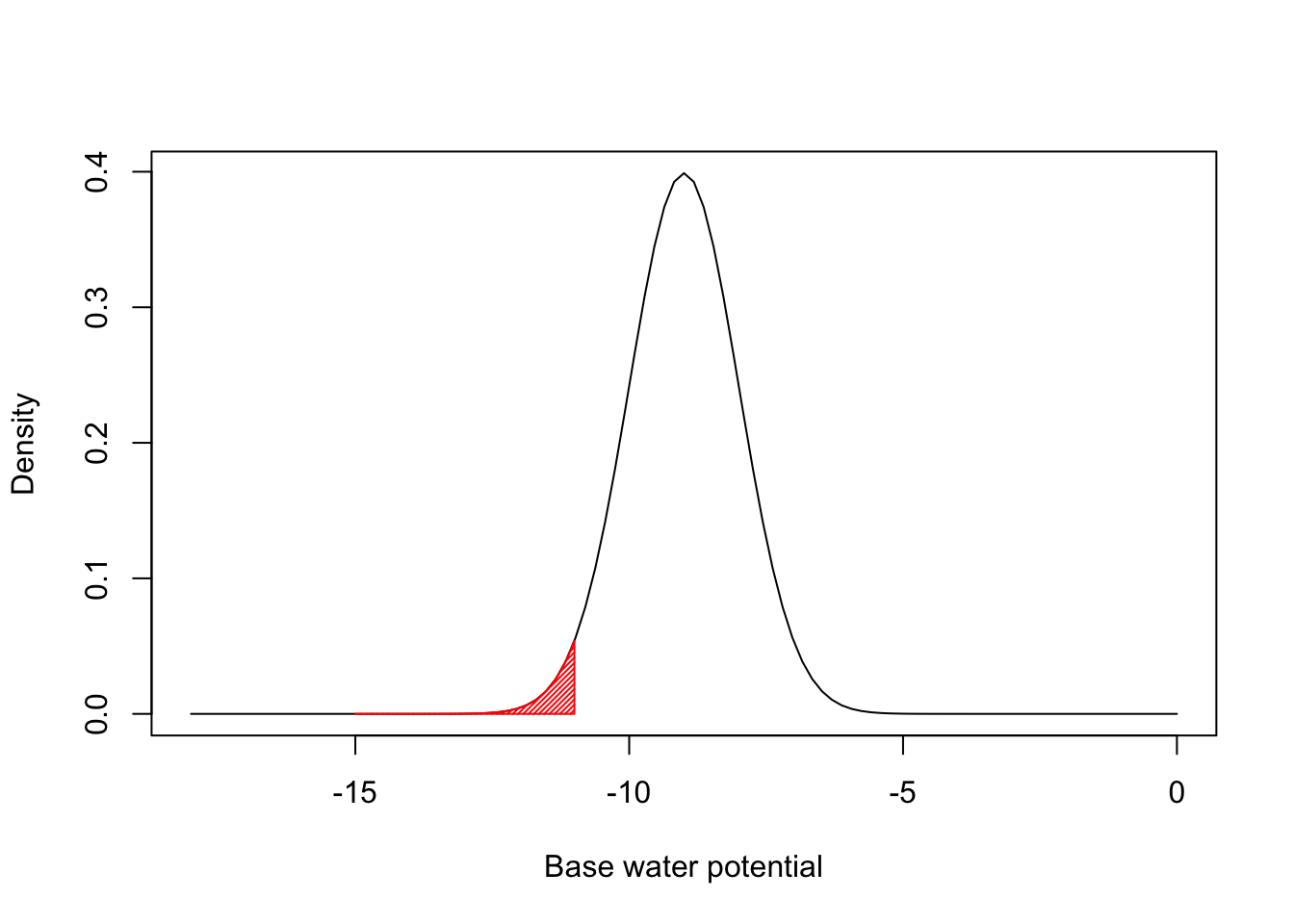
The red left tail represents the proportion of seeds that germinate during the first day, as they have base water potentials equal to or lower than -11. By using the gaussian cumulative distribution function we can easily see that that proportion is 0.228:
pnorm(-1 - 10/1, mean = -9, sd = 1)
## [1] 0.02275013More generally, we can write:
\[ P(t, \Psi) = \Phi \left\{ \frac{\Psi - (\theta_H / t) -\mu }{\sigma} \right\} \quad \quad \quad (10)\]
where \(\Phi\) is the selected cumulative distribution function. The above model returns the proportion of germinated seeds (G), as a function of time and water potential in the substrate. According to Bradford (2002), \(\Phi\) is cumulative gaussian.
Let’s think more deeply about Equation 9 (Bradford, 2002). This function was built to represent the cumulative distribution function of base water potential within the population. However, it can be as well taken to represent the cumulative distribution function of germination time within the population. Obviously, while the first distribution is gaussian, the second one is not: indeed, the germination time appears at the denominator of the expression \(\theta_H / t\). It doesn’t matter: every cumulative distribution function for germination time can be fit by using time-to-event methods!
We implemented this model in R as the function HTnorm() that is available within the drcSeedGerm package and it is meant to be used with the drm() function, in the drc package.
Mesgaran et al (2013) suggested that the distribution of base water potential within the population may not be gaussian and proposed several alternatives, which we have all implemented within the package. In all, drcSeedGerm contains six possible distributions:
- gaussian distribution (function
HTnorm()) - logistic distribution (function
HTL()) - Gumbel (function
HTG()) - log-logistic (function
HTLL()) - Weibull (Type I) (function
HTW1()) - Weibull (Type II) (function
HTW2())
The equations are given at the end of this page; for gaussian, logistic and log-logistic distributions, \(\Psi_{b(50)}\) is the median base water potential within the population. For the gaussian distribution, \(\sigma_{\Psi b}\) corresponds to the standard deviation of \(\Psi_b\) within the population.
Distributions based on logarithms (the log-logistic and all other distributions thereafter) are only defined for positive amounts. On the contrary, we know that base water potential is mostly negative. Therefore, shifted distributions need to be used, by introducing a shifting parameter \(\delta\) which ‘moves’ the distribution to the left, along the x-axis, so that negative values are possible (see Mesgaran et al., 2013).
Let’s fit the above functions to the ‘rape’ dataset. But, before, let me highlight that providing starting values is not necessary, as self-starting routines are already implemented for all models.
mod1 <- drmte(nSeeds ~ timeBef + timeAf + Psi,
data = rape, fct = HTnorm())
mod2 <- drmte(nSeeds ~ timeBef + timeAf + Psi,
data = rape, fct = HTL())
mod3 <- drmte(nSeeds ~ timeBef + timeAf + Psi,
data = rape, fct = HTG())
mod4 <- drmte(nSeeds ~ timeBef + timeAf + Psi,
data = rape, fct = HTLL())
mod5 <- drmte(nSeeds ~ timeBef + timeAf + Psi,
data = rape, fct = HTW1())
mod6 <- drmte(nSeeds ~ timeBef + timeAf + Psi,
data = rape, fct = HTW2())What is the best model for this dataset? Let’s use the Akaike’s Information Criterion (AIC) to decide:
AIC(mod1, mod2, mod3, mod4, mod5, mod6, modHTE)
## df AIC
## mod1 291 3516.914
## mod2 291 3300.824
## mod3 291 3097.775
## mod4 290 2886.608
## mod5 290 2889.306
## mod6 290 3009.023
## modHTE 289 2832.481The first model modHTE considers explicitly the distribution of germination times and it is the best fitting of all. The other models consider explicitly the distribution of base water potential, while the distribution of germination times is indirectly included. Among these models, the gaussian is the worse fitting, while the log-logistic is the best one (mod4).
For this latter model, we take a look at the value of estimated parameters, with cluster robust standard errors.
lmtest::coeftest(mod4, vcov = vcovCL, cluster = rape$Dish)
##
## t test of coefficients:
##
## Estimate Std. Error t value Pr(>|t|)
## thetaH:(Intercept) 0.676804 0.074160 9.1263 <2e-16 ***
## delta:(Intercept) 1.136671 0.101804 11.1652 <2e-16 ***
## Psib50:(Intercept) -0.947798 0.020575 -46.0647 <2e-16 ***
## sigma:(Intercept) 0.371971 0.172825 2.1523 0.0322 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Germination rates and times for a certain percentile (e.g. GR50, GR30), can be obtained by using the GRate() and GTime() function in drcSeedGerm. Again, the use of cluster-robust standard errors is highly recommended.
GRate(mod4, respLev=c(30, 50, 70), x2 = 0, vcov. = vcovCL)
## Estimate SE
## GR:1:30 0.6775790 0.08365887
## GR:1:50 0.7140812 0.08509008
## GR:1:70 0.7710049 0.09376307
GTime(mod4, respLev=c(30, 50, 70), x2 = 0, vcov. = vcovCL)
## Estimate SE
## T:1:30 1.475843 0.1822184
## T:1:50 1.400401 0.1668721
## T:1:70 1.297009 0.1577312We can also make predictions about the germinated proportion for a certain time and water potential level. The code below returns the maximum germinated proportions at -1.5, -0.75, and 0 MPa.
predictSG(mod4, se.fit=T, vcov. = vcovCL,
newdata = data.frame(Time=c(10, 10, 10),
Psi=c(-1.5, -0.75, 0))
)
## Prediction SE
## [1,] 6.541125e-15 1.102220e-13
## [2,] 8.035981e-01 5.617769e-02
## [3,] 9.906224e-01 9.435188e-03Let’s use the predictSG() function to plot the ‘modHTE’ and ‘mod4’ objects together in the same graph.
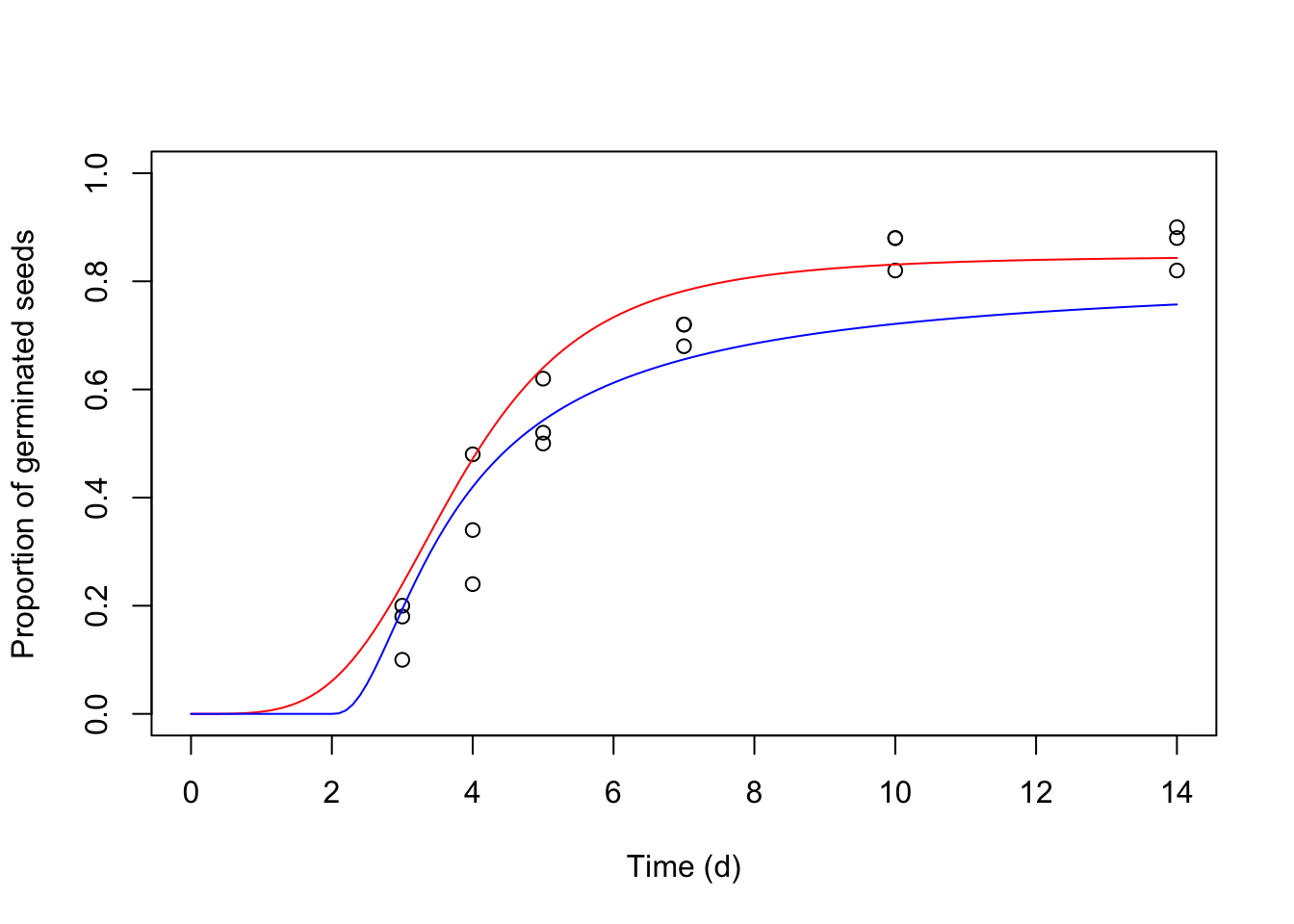
Thanks for reading!
Prof. Andrea Onofri
Department of Agricultural, Food and Environmental Sciences
University of Perugia (Italy)
Borgo XX Giugno 74
I-06121 - PERUGIA
References
- Berger, S., Graham, N., Zeileis, A., 2017. Various versatile variances: An object-oriented implementation of clustered covariances in R. Faculty of Economics and Statistics, University of Innsbruck, Innsbruck.
- Bradford, K.J., 2002. Applications of hydrothermal time to quantifying and modeling seed germination and dormancy. Weed Science 50, 248–260.
- Mesgaran, M.B., Mashhadi, H.R., Alizadeh, H., Hunt, J., Young, K.R., Cousens, R.D., 2013. Importance of distribution function selection for hydrothermal time models of seed germination. Weed Research 53, 89–101. https://doi.org/10.1111/wre.12008
- Onofri, A., Benincasa, P., Mesgaran, M.B., Ritz, C., 2018. Hydrothermal-time-to-event models for seed germination. European Journal of Agronomy 101, 129–139.
- Onofri, A., Mesgaran, M.B., Neve, P., Cousens, R.D., 2014. Experimental design and parameter estimation for threshold models in seed germination. Weed Research 54, 425–435. https://doi.org/10.1111/wre.12095
- Pace, R., Benincasa, P., Ghanem, M.E., Quinet, M., Lutts, S., 2012. Germination of untreated and primed seeds in rapeseed (brassica napus var oleifera del.) under salinity and low matric potential. Experimental Agriculture 48, 238–251.
- Ritz, C., Jensen, S. M., Gerhard, D., Streibig, J. C. (2019) Dose-Response Analysis Using R CRC Press. Achim Zeileis, Torsten Hothorn (2002). Diagnostic Checking in Regression Relationships. R News 2(3), 7-10. URL: https://CRAN.R-project.org/doc/Rnews/
Some further detail
Let us conclude this page by giving some detail on all equations.
The equation for the model HTnorm(). Here, we show all other equations, as implemented in our package.
HTL()
\[ P(t, \Psi) = \frac{1}{1 + exp \left[ - \frac{ \Psi - \left( \theta _H/t \right) - \Psi_{b(50)} } {\sigma} \right] }\]
HTG()
\[ P(t, \Psi) = \exp \left\{ { - \exp \left[ { - \left( {\frac{{\Psi - (\theta _H / t ) - \mu }}{\sigma }} \right)} \right]} \right\} \]
HTLL()
\[ P(t, \Psi) = \frac{1}{1 + \exp \left\{ \frac{ \log \left[ \Psi - \left( \frac{\theta _H}{t} \right) + \delta \right] - \log(\Psi_{b50} + \delta) }{\sigma}\right\} }\]
HTW1()
\[ P(t, \Psi) = exp \left\{ - \exp \left[ - \frac{ \log \left[ \Psi - \left( \frac{\theta _H}{t} \right) + \delta \right] - \log(\Psi_{b50} + \delta) }{\sigma}\right] \right\}\]
HTW2()
\[ P(t, \Psi) = 1 - exp \left\{ - \exp \left[ \frac{ \log \left[ \Psi - \left( \frac{\theta _H}{t} \right) + \delta \right] - \log(\Psi_{b50} + \delta) }{\sigma}\right] \right\}\]