Capitolo 2 Il metodo sperimentale: quando la scienza è scienza
2.1 Introduzione
In una società caratterizzata dal sovraccarico cognitivo immagino sia giusto chiedersi (e chiedere) che cosa sia la scienza, cosa distingua le informazioni scientifiche da tutto quello che invece non è altro che pura opinione, magari autorevole, ma senza il sigillo dell’oggettività.
Per quanto affascinante possa sembrare l’idea del ricercatore che con un’improvviso colpo di genio elabora una stupefacente teoria, dovrebbe essere chiaro che l’intuizione è solo un possibile punto di partenza, che non necessariamente prelude al progresso scientifico, per quanto geniale ed innovativa possa essere. In generale, almeno in ambito biologico, nessuna teoria acquisisce automaticamente valenza scientifica, ma rimane solo nell’ambito delle opinioni, indipendentemente dal fatto che nasca da un colpo di genio, oppure grazie ad un paziente e meticoloso lavoro di analisi intellettuale, che magari si concretizza in un modello matematico altamente elegante e complesso.
Da un punto di vista puramente intuitivo, è ovvio aspettarsi che una prova scientifica debba uscire dall’ambito delle opinioni legate a divergenze di cultura, percezione e/o credenze individuali, per divenire, al contrario, oggettiva e universalmente valida, distinguendosi quindi da altre verità di natura metafisica, religiosa o pseudoscientifica. Che cosa è che permette alla scienza di divenire tale?
A questo proposito, riporto alcuni aforismi significativi:
- Proof is a justified true belief (Platone, Dialoghi)
- The interest I have in believing a thing is not a proof of the existence of that thing (Voltaire)
- A witty saying proves nothing (Voltaire)
2.1.1 Cosa è quindi una prova scientifica?
La base di tutta la scienza risiede nel cosiddetto ‘metodo scientifico’, che si fa comunemente risalire a Galileo Galilei (1564-1642) e che è riassunto nella figura seguente.
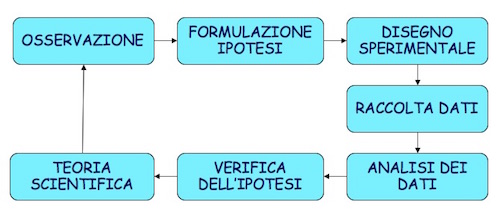
Il metodo scientifico Galileiano
Senza andare troppo in profondità, è importante notare due aspetti:
- il ruolo fondamentale dell’esperimento scientifico, che produce dati a supporto di ipotesi pre-esistenti;
- lo sviluppo di teorie basate sui dati, che rimangono valide fino a che non si raccolgono altri dati che le confutano, facendo nascere nuove ipotesi che possono portare allo sviluppo di nuove teorie, più affidabili o più semplici.
Insomma, l’ingrediente fondamentale di una prova scientifica è che è supportata da un insieme dei dati sperimentali; di fatto, non esiste scienza senza dati! Resta famoso l’aforisma “In God we trust, all the others bring data”, attribuito all’ingegnere e statistico americano W. Edwards Deming (1999-1923), anche se pare che egli in realtà non l’abbia mai pronunciato.
2.2 Esperimenti buoni e cattivi!
Non tutti gli esperimenti sono buoni e, di conseguenza, non tutti i dati sono buoni. In particolare, due sono gli elementi che possono portare a dati di diversa affidabilità:
- Errore sperimentale
- Campionamento
Vediamo qualche dettaglio in più a proposito di questi due elementi.
2.2.1 L’errore sperimentale
Alla base della raccolta di dati sperimentali vi è un processo di misurazione, attraverso la quale il fenomeno oggetto di studio viene caratterizzato con appositi strumenti scientifici, più o meno complessi. Il problema è che nessuna misura può essere considerata precisa in senso assoluto, cioè perfettamente coincidente col valore reale della grandezza misurata, che è destinato a rimanere un’entità incognita e indeterminabile.
In particolare, in ogni esperimento scientifico esiste un potenziale elemento di confusione che gli scienziati conoscono con il termine di errore sperimentale, con la cui presenza è necessario confrontarsi sempre e comunque.
Nel misurare una determinata grandezza fisica, indipendentemente dal metodo scelto per la misura, possiamo sempre commettere due tipi di errore: sistematico ed accidentale (casuale).
L’errore sistematico è provocato da difetti intrinseci dello strumento o incapacità peculiari dell’operatore e tende a ripetersi costantemente in misure successive. Un esempio tipico è quello di una bilancia non tarata, che tende ad aggiungere 20 grammi ad ogni misura che effettuiamo. Per queste sue peculiarità, l’errore sistematico non è quantificabile e deve essere contenuto al minimo livello possibile tramite la perfetta taratura degli strumenti e l’adozione di metodi di misura rigidamente standardizzati e accettati dalla comunità scientifica mondiale.
L’errore accidentale (o casuale) è invece legato a fattori variabili nel tempo e nello spazio, quali:
- malfunzionamenti accidentali dello strumento. Si pensi ad esempio al rumore elettrico di uno strumento, che fa fluttuare i risultati delle misure effettuate;
- imprecisioni o disattenzioni casuali dell’operatore. Si pensi ad esempio ad un banale errore di lettura dello strumento, che può capitare soprattutto ad un operatore che esegua moltissime misure manuali con procedure di routine;
- irregolarità dell’oggetto da misurare} unite ad una precisione relativamente elevata dello strumento di misura. Si pensi alla misurazione del diametro di un melone con un calibro: è facile che compaiano errori legati all’irregolarità del frutto o al fatto che l’operatore non riesce a misurare lo stesso nel punto in cui il suo diametro è massimo. Oppure, più semplicemente si pensi alla misurazione della produzione di granella di una certa varietà di frumento: anche ipotizzando di avere uno strumenti di misura perfetto e quindi esente da errore, la produzione mostrerebbe comunque una fluttuazione naturale da pianta a pianta, in base al patrimonio genetico e, soprattutto, in base alle condizioni di coltivazione che non possono essere standardizzate oltre ad un certo livello (si pensi alla variabilità del terreno agrario).
Dato che queste imprecisioni sono assolutamente casuali è chiaro che le fluttuazioni positive (misura maggiore di quella vera) sono altrettanto probabili di quelle negative e tendono a presentarsi con la stessa frequenza quando si ripetano le misure più volte. Di conseguenza, l’errore sperimentale casuale può essere gestito attraverso la replicazione delle misure: infatti, se ripeto una misura soggetta a questo tipo di errore, nel lungo periodo gli errori positivi e negativi tendono ad annullarsi reciprocamente e la media delle misure effettuate tende quindi a coincidero con il valore reale della grandezza da misurare.
2.2.2 Il campionamento
Se è vero, e la pratica sperimentale lo conferma, che ripetere le misure porta ad ottenere molti risultati diversi, nasce il problema di capire quante repliche sono necessarie. Se si ripensa a quanto detto finora, dovrebbe risultare evidente che, per ottenere una misura pari all’effettivo (reale) valore della grandezza da misurare, bisognerebbe effettuarne infinite. Tuttavia è altrettanto evidente che questo procedimento è totalmente improponibile!!!
Qual è la strada seguita dagli scenziati, quindi? E’ quella di raccogliere un numero finito di misure, sufficientemente basso da essere compatibile con le umane risorse di tempo e denaro, ma sufficientemente alto da essere giudicato attendibile. Qualunque sia questo valore finito, è evidente che ci troviamo difronte solo ad un campione delle infinite misure che avremmo dovuto fare, ma che non abbiamo fatto. La domanda è: questo campione è rappresentativo o no? E’ in grado di descrivere adeguatamente la realtà? E’ possibile che gli errori sperimentali positivi e negativi non si siano annullati tra loro, confondendosi con l’effetto biologico in studio? In altre parole: possiamo fidarci dei dati che abbiamo raccolto?
La possibilità di raccogliere dati sbagliati è tutt’altro che remota. Gli scienziati american Pons e Fleischmann il 23 Marzo del 1989 diffusero pubblicamente la notizia di essere riusciti a riprodurre la fusione nucleare fredda, causando elevatissimo interesse nella comunità scientifica. Purtroppo le loro misure erano vizite da una serie di problemi e il loro risultato fu clamorosamente smentito da esperimenti successivi.

Conseguenze di un esperimento sbagliato
2.3 Scienza = metodo
Insomma, la scienza deve essere basata sui dati, ma i dati contengono inevitabili fonti di incertezza, legate all’errore sperimentale e al processo di campionamento. Come si può procedere in queste condizioni? Il punto fondamentale è quello di adottare un metodo sperimentale che consenta di ottenere dati il più affidabili possibile. Insomma, questa semplice affermazione significa che bisogna fare eseperimenti ben condotti, precisi, seguendo procedure standardizzate e/o largamente condivise dalla comunità scientifica.
Certo è che, per quanto detto in precedenza, il fatto che i dati provengano da un processo di campionamento impedisce, di fatto, di ottenere un’affidabilità totale. Cosa succederebbe se ripetessimo l’esperimento?
Insomma, bisogna fare alcune considerazioni, che elenco di seguito:
- in primo luogo si dovrà accettare il fatto che, contrariamente a quanto si potrebbe o vorrebbe credere, non esistono prove scientifiche totalmente certe, ma l’incertezza è un elemento intrinseco della scienza.
- In secondo luogo si dovranno utilizzare gli strumenti della statistica necessari per quantificare l’incertezza residua, che dovrà essere sempre riportata a corredo dei risultati di ogni esperimento scientifico.
- Ogni risultato sarà quindi valutato dalla comunità scientifica sullo sfondo della sua incertezza, seguendo alcune regole di natura probabilistica che consentono di stabilire se la prova scientifica è sufficientemente forte per essere considerata tale.
Un elemento fondamentale di valutazione della bontà di un esperimento e dei dati da esso ottenuti sta nella cosiddetta replicabilità, cioè nella probabilità di ottenere risultati molto simili (se non uguali) replicando l’esperimento in condizioni analoghe. Per valutare se un esperimento è replicabile è necessario che questo sia descritto con un grado di dettaglio tale da permettere a chinque di ripeterlo, ottenendo risultati comparabili e non contraddittori. Nessun risultato di cui non sia provata la riproducibilità è da considerarsi valido.
E’chiaro comunque che ogni esperimento può essere smentito. Questo non è un problema: la scienza è pronta a considerare una prova scientifica valida fino a che non si raccolgono dati altrettanto affidabili che la confutino. In questo caso, si abbandona la teoria confutata e si abbraccia la nuova. L’abbandono può anche non essere totale: ad esempio la teoria gravitazionale di Newton è ancora oggi valida per molto situazioni pratiche, anche se è stata abbandonoata in favore della teoria della relatività, che spiega meglio il moto dei corpi ad altissime velocità.
In effetti, la scienza considere sempre con attenzione il principio del rasoio di Occam, per il quale si accetta sempre la teoria più semplice per interpretare una dato fenomeno, riservando le teorie più complesse alle situazioni più difficili, che giustificano tale livello di complessità.
2.4 Chi valuta se un esperimento è attendibile?
Quanto detto finora vorrebbe chiarire come il punto centrale della scienza non è la certezza delle teorie, bensì il metodo che viene utilizzato per definirle. Ognuno di noi è quindi responsabile di verificare che le informazioni in suo possesso siano ‘scientificamente’ attendibili, cioè ottenute con un metodo sperimentale adeguato. Il fatto è che non sempre siamo in grado di compiere questa verifica, perché non abbiamo strumenti ‘culturali’ adeguati, se non nel ristretto ambito delle nostre competenze professionali. Come fare allora?
L’unica risposta accettabile è quella di controllare l’attendibilità delle fonti di informazione. In ambito biologico, le riviste autorevoli sono caratterizzate dal procedimento di ‘peer review’, nel quale i manoscritti scientifici, prima della pubblicazione, sono sottoposti ad un comitato editoriale ed assegnati ad un ‘editor’, il quale legge il lavoro e contemporaneamente lo invia a due o tre scienziati anonimi e particolarmente competenti in quello specifico settore scientifico (reviewers o revisori).
I revisori, insieme all’editor, compiono un attento lavoro di esame e stabiliscono se l’evidenza scientifica presentata è sufficientemente ‘forte’. Le eventuali critiche vengono presentate all’autore, che è tenuto a rispondere in modo convincente, anche ripetendo gli esperimenti se necessario. Il processo richiede spesso interi mesi ed è abbastanza impegnativo per uno scenziato. E’ piuttosto significativa l’immagine presentata in scienceBlog.com, che allego qui.

Il processo di peer review
In sostanza il meccanismo di peer review è l’analogo scientifico di un processo, nel quale l’inputato (lavoro scientifico) viene assolto (rilasciato, leggi: rigettato) in presenza di qualunque ragionevole dubbio metodologico. Attenzione: il dubbio che non deve esistere è quello metodologico, dato che il dubbio sul risultato non può essere allontanato completamente e i reviewer controlleranno solo che esso si trovi al disotto della soglia massima, stabilita con metodiche statistiche.
Questo procedimento, se effettuato con competenza, dovrebbe aiutare a separare la scienza dalla pseudo-scienza e, comunque, ad eliminare la gran parte degli errori metodologici dai lavori scientifici.
2.5 Il metodo sperimentale
Almeno in ambito biologico, la definizione del metodo sperimentale è fondamentalmente attribuita allo scienziato inglese Ronald Fisher (1890-1962), che l’ha esplicitata nel suo famoso testo del 1935 (The design of experiments). Mi sembra opportuno riassumerla nelle tre espressioni ‘chiave’: controllo locale degli errori, replicazione e randomizzazione. Si tratta di:
- contenere al massimo possibile l’errore sperimentale, con l’adozione di tecniche opportune, in modo da separare le fonti di variabilità, isolando qualla oggetto di studio (controllo locale degli errori);
- replicare le misure più volte (replicazione)
- Scegliere le unità sperimentali da misurare in modo totalmente casuale, così da avere un campione rappresentativo ed evitare di confondere gli effetti prodotti dall’errore sperimentale con quelli prodotti dal fenomeno biologico oggetto di studio (randomizzazione)
Vediamo ora un’esempio banale di come procedere.
2.6 Metodi sperimentali validi ed invalidi
Immaginiamo un ricercatore che abbia un’idea brillante: egli ha inventato un nuovo fertilizzante ‘prodigioso’. E’ evidente che non può presentarsi alla comunità scientifica declamando le doti di questo fertilizzante, in quanto egli verrebbe immediatamente esposto al pubblico ludibrio, perchè sta presentando delle opinioni, non delle evidenze scientifiche (almeno, così dovrebbe essere, in una società sana… purtroppo in un’era di pseudo-scienza siamo sempre pronti a dar credito a chiunque, senza un’adeguata dose di scetticismo… )
2.6.1 Primo esperimento
Come ogni scenziato, egli deve raccogliere dati. E lo fa, organizzando un esperimento, nel quale prende un campo di mais e lo fertilizza con il suo nuovo composto, ritraendo una produzione del 20% superiore a quella usuale. Ovvoamente, se prova a pubblicare questa notizia, il suo lavoro verrà certamente (si spera…) rigettato, in quanto rimane il dubbio su chi sia la causa dell’effetto riscontrato: il fertilizzante? il clima dell’anno di prova? il suolo? la varietà di mais impiegata? E’ chiaro che questo non è un esperimento controllato: il campo trattato e quello non trattato (riferimento) non sono totalmente uguale, eccetto che per il fertilizzante impiegato.
2.6.2 Secondo esperimento
A questo punto il ricercatore pianifica un esperimento comparativo controllato: prende due campio di mais, vicini, con lo stesso terreno, semina la stessa varietà di mais e coltiva i due campi esattamente nello stesso modo, con l’unica differenza che in uno di essi somministra il fertilizzante in studio (campo trattato) e nell’altro no (testimone o controllo). Alla fine osserva che il campo trattato produce 130 tonnellate per ettaro, mentre quello non trattato ne produce 115 e conclude che il nuovo fertilizzante è efficace (+ 12% circa). Infatti egli ritiene che, dato che i due campi sono totalmente uguali, l’incremento di produzione non possa che essere attribuito al fertilizzante. Scrive un report, che, purtroppo, viene rigettato.
Anche se questo secondo esperimento è meglio del primo, permane tuttavia il dubbio che l’effetto si sia prodotto per caso. Potrebbe infatti esserci stata una qualche situazione non osservata che ha avvantaggiato uno dei due campi. Ad esempio un attacco di insetti, una carenza idrica, o qualsivoglia altra situazione. Questo vi sembra improbabile? Non importa, con una sola osservazione il ricercatore non è in grado di provare che il risultato è replicabile.
2.6.3 Terzo esperimento
Avendo imparato la lezione, il ricercatore fa un nuovo esperimento, utilizzando stavolta otto campi: quattro trattati e quattro non trattati. Anche in questo caso osserva un incremento produttivo medio del 12% circa ed è sicuro che l’effetto è replicabile, perché lo ha osservato più volte. Purtroppo, anche questo esperimento non viene considerato affidabile e, di conseguenza, il lavoro non è pubblicabile. Stavolta il problema è che il ricercatore ha scelto i campi trattati con un criterio sistematico (un campo trattato ed uno ‘tradizionale’ contiguo), cosìcchè i campi trattati sono tutti a sinistra di quelli ‘tradizionali’. Ciò crea un ragionevole dubbio: e se vi fosse un gradiente di fertilità da destra verso sinistra? Questo potrebbe dare origine ad una produttività maggiore dei campi a destra, rispetto a quelli a sinistra. In presenza di questo ‘ragionevole’ dubbio, la prova non può avere valenza scientifica.
2.6.4 Quarto esperimento: quello buono
Il ricercatore prende allora otto campi ed assegna il trattamento a quattro di essi, scelti in modo totalmente casuale. In questo caso è sicuro che, anche se vi fosse un qualche elemento estraneo di confusione (gradiente di fertilità, attacco di insetti…), esso dovrebbe colpire le unità sperimentali casualmente disposte senza creare vantaggi particolari all’uno o all’altro dei due trattamenti. Ovviamente egli non è certo (e non può esserlo) che l’esperimento sia del tutto attendibile; infatti potrebbe essere stato così sfortunato che un qualche elemento estraneo ignoto si è accanito proprio sulle parcelle non trattate, danneggiandone la produttività. Solo che, grazie alla scelta casuale, questa evenienza diviene altamente improbabile, così da rendere i dubbi irragionevoli. In questo caso l’esperimento è controllato, replicato e randomizzato e il risultato ottenuto, in quanto ragionevolmente attendibile, può essere pubblicato.
2.7 Incertezza residua
Insomma, un esperimento valido è controllato, replicato e randomizzato. Tuttavia le misure raccolte sono poche e sono solo un campione di tutte quelle possibili. Infatti il nostro ricercatore ha usato otto campi, ma ne avrebbe potuti usare 16, 32 e così via. Rimane quindi il dubbio, che, se facessimo altre misure (cioè ampliassimo il campione), queste potrebbero invalidare i risultati ottenuti fino a quel momento.
Se mi è concesso un paragone calcistico, è un po’ come chiedersi come finirà una partita di calcio dopo aver assistito solo al primo tempo: in alcune circostanze, quando una delle due squadre ha mostrato una chiara superiorità, la previsione è abbastanza facile, mentre in altre circostanze l’equivalenza dei valori in campo la rende alquanto difficile. In tutti i casi, si tratta solo di una previsione, che può essere sempre smentita alla prova dei fatti.
Anche la scienza funziona così. Noi osserviamo solo il primo tempo, che, nel caso del nostro ricercatore, consiste di otto misure. Osserviamo che le quattro misure del fertilizzato sono tutte in modo consistente molto più alte di quelle del non trattato e quindi possiamo concludere, con ragionevole certezza, che il fertilizzante è efficace. Altrimenti, se la produzione media del trattato è solo lievemente più alta, il nostro esperimento potrà essere inconclusivo, cioè incapace di fugare i dubbi sull’effettiva efficacia del nostro fertilizzante. Avremo bisogno di fare altre prove di conferma.
2.8 Il ruolo della statistica
Abbiamo visto che un esperimento scientifico, anche se ben fatto (controllato, replicato e randomizzato), può portare a evidenze scientifiche più o meno forti. In quest’ottica, la statistica ci fornisce gli strumenti per riassumere le misure effettuate, calcolarne l’incertezza e rappresentare la forza dell’evidenza scientifica, in modo da poter prendere decisioni sull’efficacia dei trattamenti e sull’esigenza di ulteriori verifiche. Imparare a conoscere e comprendere questi strumenti statistici è l’obiettivo di questo corso.
2.9 Conclusioni
In conclusione, possiamo ripartire dalla domanda iniziale: “Che cosa è la scienza?”, per rispondere che è scienza tutto ciò che è supportato da dati che abbiano passato il vaglio della peer review, dimostrando di essere stati ottenuti con un procedimento sperimentale privo di vizi metodologici e di essere sufficientemente affidabili in confronto alle fonti di incertezza cui sono associati.
Qual è il take-home message di questo articolo? Fidatevi solo delle riviste scientifiche attendibili, cioè quelle che adottano un serio processo di peer review prima della pubblicazione.